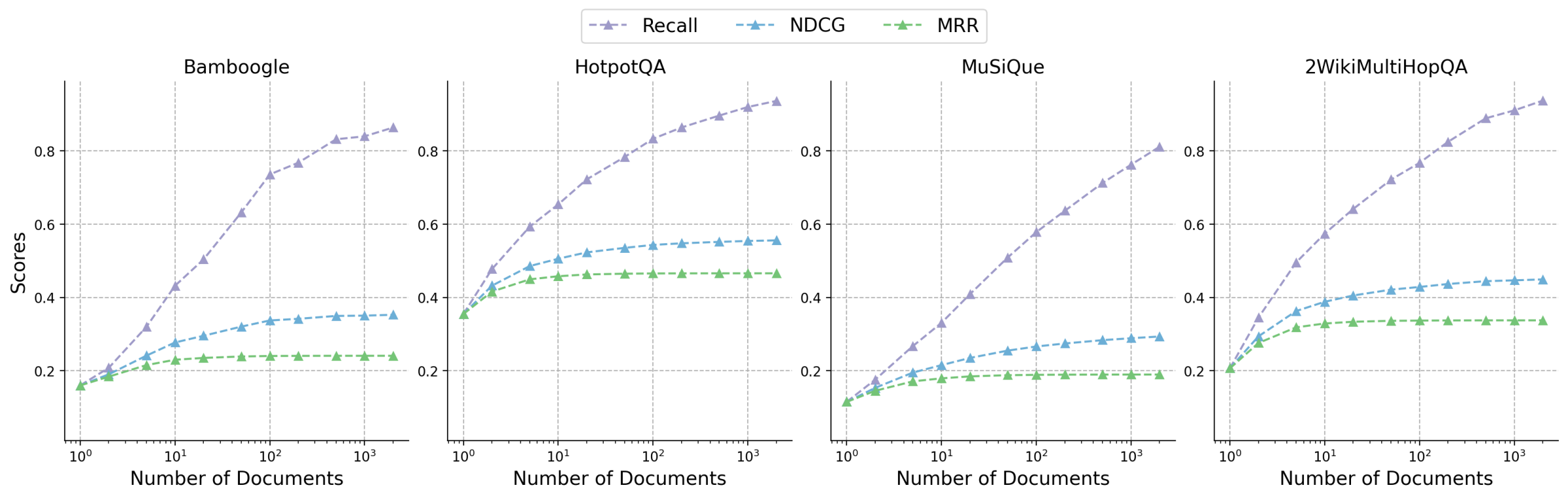
# Technical Data Extraction: Retrieval Performance Metrics
This document provides a comprehensive extraction of the data and trends presented in the provided image, which consists of four line charts evaluating retrieval performance across different datasets.
## 1. Metadata and Global Components
* **Image Type:** Multi-panel line chart (4 subplots).
* **Primary Language:** English.
* **Global Legend:** Located at the top center of the image.
* **Recall:** Purple dashed line with triangle markers ($\triangle$).
* **NDCG:** Blue dashed line with triangle markers ($\triangle$).
* **MRR:** Green dashed line with triangle markers ($\triangle$).
* **X-Axis (All Subplots):** "Number of Documents". Logarithmic scale ranging from $10^0$ (1) to $2 \times 10^3$ (2000).
* **Y-Axis (All Subplots):** "Scores". Linear scale ranging from 0.2 to 0.8 (with some data points extending to ~0.1 and ~0.9).
* **Grid:** Light gray dashed grid lines for both major x-axis log intervals and y-axis increments of 0.2.
---
## 2. Subplot Analysis
### Subplot 1: Bamboogle
* **Trend Analysis:**
* **Recall (Purple):** Shows a strong, consistent upward slope. It starts as the lowest metric at $x=1$ and becomes the highest by a significant margin as the number of documents increases.
* **NDCG (Blue):** Slopes upward moderately, beginning to plateau around $x=100$.
* **MRR (Green):** Slopes upward slightly at first, then plateaus almost completely after $x=10$.
* **Data Points (Approximate):**
* **At $x=1$:** Recall $\approx$ 0.16, NDCG $\approx$ 0.16, MRR $\approx$ 0.16.
* **At $x=10$:** Recall $\approx$ 0.43, NDCG $\approx$ 0.28, MRR $\approx$ 0.23.
* **At $x=2000$:** Recall $\approx$ 0.86, NDCG $\approx$ 0.35, MRR $\approx$ 0.24.
### Subplot 2: HotpotQA
* **Trend Analysis:**
* **Recall (Purple):** Strong logarithmic growth, curving upward throughout the range.
* **NDCG (Blue):** Moderate growth, showing signs of saturation/plateau after $x=100$.
* **MRR (Green):** Rapid initial growth from $x=1$ to $x=10$, followed by a flat plateau.
* **Data Points (Approximate):**
* **At $x=1$:** All metrics converge at $\approx$ 0.35.
* **At $x=10$:** Recall $\approx$ 0.65, NDCG $\approx$ 0.50, MRR $\approx$ 0.45.
* **At $x=2000$:** Recall $\approx$ 0.94, NDCG $\approx$ 0.55, MRR $\approx$ 0.46.
### Subplot 3: MuSiQue
* **Trend Analysis:**
* **Recall (Purple):** Steady, nearly linear growth on the log scale.
* **NDCG (Blue):** Slow, steady growth, maintaining a significant gap below Recall.
* **MRR (Green):** Very slight initial growth, reaching a plateau very early (around $x=5$).
* **Data Points (Approximate):**
* **At $x=1$:** All metrics converge at $\approx$ 0.11.
* **At $x=10$:** Recall $\approx$ 0.33, NDCG $\approx$ 0.21, MRR $\approx$ 0.18.
* **At $x=2000$:** Recall $\approx$ 0.81, NDCG $\approx$ 0.29, MRR $\approx$ 0.19.
### Subplot 4: 2WikiMultiHopQA
* **Trend Analysis:**
* **Recall (Purple):** Strong upward trajectory, similar to HotpotQA.
* **NDCG (Blue):** Moderate growth, leveling off after $x=50$.
* **MRR (Green):** Initial growth until $x=10$, then remains perfectly flat.
* **Data Points (Approximate):**
* **At $x=1$:** All metrics converge at $\approx$ 0.21.
* **At $x=10$:** Recall $\approx$ 0.57, NDCG $\approx$ 0.38, MRR $\approx$ 0.33.
* **At $x=2000$:** Recall $\approx$ 0.93, NDCG $\approx$ 0.45, MRR $\approx$ 0.34.
---
## 3. Summary of Findings
| Dataset | Starting Score (x=1) | Final Recall (x=2000) | Final NDCG (x=2000) | Final MRR (x=2000) |
| :--- | :--- | :--- | :--- | :--- |
| **Bamboogle** | ~0.16 | ~0.86 | ~0.35 | ~0.24 |
| **HotpotQA** | ~0.35 | ~0.94 | ~0.55 | ~0.46 |
| **MuSiQue** | ~0.11 | ~0.81 | ~0.29 | ~0.19 |
| **2WikiMultiHopQA** | ~0.21 | ~0.93 | ~0.45 | ~0.34 |
**Key Observations:**
1. **Recall** is the most sensitive metric to the number of documents, showing continuous improvement as more documents are retrieved across all datasets.
2. **MRR (Mean Reciprocal Rank)** is the least sensitive, typically plateauing after only 10 documents are retrieved. This suggests that the "correct" answer is rarely found deeper in the results if it wasn't in the top 10.
3. **HotpotQA** shows the highest overall performance across all metrics, while **MuSiQue** shows the lowest.
4. In all cases, at $x=1$ (retrieving only one document), Recall, NDCG, and MRR are identical, which is mathematically expected for these metrics at $k=1$.