## Box Plot: NSGA-II with N=n+1 on OneMinMax
### Overview
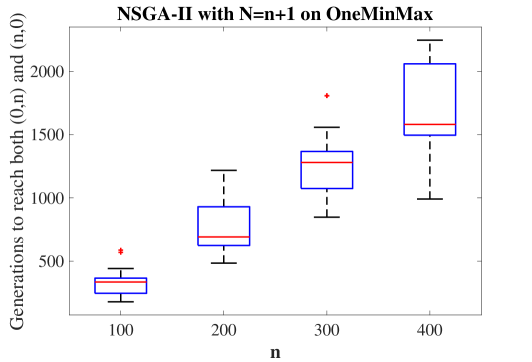
The image displays a box plot comparing the number of generations required for the NSGA-II algorithm (with N=n+1) to reach both (0,n) and (n,0) on the OneMinMax problem. The x-axis represents the parameter `n` (100, 200, 300, 400), and the y-axis represents generations (0–2200). Two box plots are shown per `n` value: one in blue (main distribution) and one in red (median), with red "+" symbols indicating outliers.
---
### Components/Axes
- **Title**: "NSGA-II with N=n+1 on OneMinMax" (centered at the top).
- **X-axis**: Labeled "n" with discrete values: 100, 200, 300, 400 (bottom axis).
- **Y-axis**: Labeled "Generations to reach both (0,n) and (n,0)" (left axis, range 0–2200).
- **Legend**: Implied via color coding:
- **Blue**: Box plots (interquartile range and whiskers).
- **Red**: Median lines and outliers ("+" symbols).
- **Spatial Grounding**:
- Title: Centered at the top.
- X-axis labels: Bottom, centered below each box.
- Y-axis labels: Left, vertical.
- Box plots: Positioned above each x-axis label (100, 200, 300, 400).
- Outliers: Red "+" symbols above/below boxes.
---
### Detailed Analysis
1. **n = 100**:
- Median (red line): ~350 generations.
- Interquartile range (IQR): ~300–400 generations.
- Outlier: ~550 generations (red "+").
2. **n = 200**:
- Median: ~650 generations.
- IQR: ~500–800 generations.
- No visible outliers.
3. **n = 300**:
- Median: ~1250 generations.
- IQR: ~1000–1500 generations.
- Outlier: ~1800 generations (red "+").
4. **n = 400**:
- Median: ~1550 generations.
- IQR: ~1200–1800 generations.
- Outlier: ~2200 generations (red "+").
---
### Key Observations
1. **Trend**: The median generations increase monotonically with `n` (350 → 650 → 1250 → 1550).
2. **Spread**: The IQR widens as `n` increases, indicating greater variability in performance for larger `n`.
3. **Outliers**: Outliers appear only for `n = 100`, `n = 300`, and `n = 400`, suggesting rare but extreme cases where the algorithm took significantly longer.
4. **Color Consistency**: Red lines (medians) and "+" (outliers) align with the implied legend. Blue boxes match the interquartile ranges.
---
### Interpretation
The data demonstrates that the NSGA-II algorithm with N=n+1 requires more generations to solve larger instances of the OneMinMax problem. The median generations scale linearly with `n`, while the increasing IQR suggests diminishing consistency in performance for larger `n`. Outliers at higher `n` values highlight potential instability or suboptimal convergence in specific runs. This trend implies that the algorithm’s efficiency degrades with problem size, necessitating further optimization or parameter tuning for scalability.