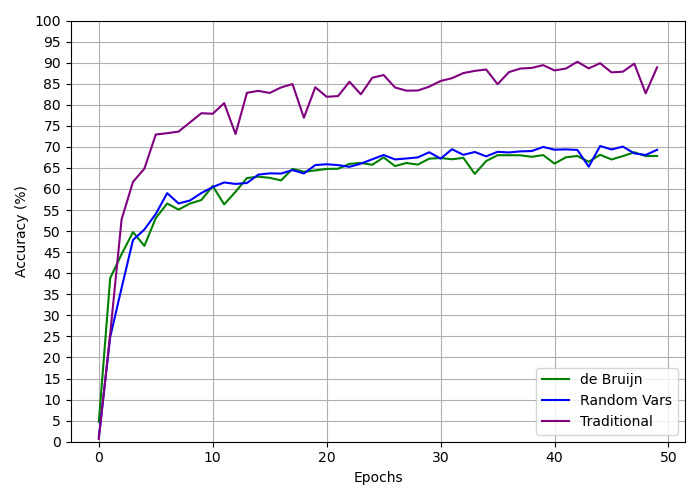
## Line Graph: Accuracy vs. Epochs for Different Methods
### Overview
The image is a line graph comparing the accuracy (%) of three methods—**de Bruijn**, **Random Vars**, and **Traditional**—over 50 training epochs. The y-axis represents accuracy (0–100%), and the x-axis represents epochs (0–50). The legend is positioned in the bottom-right corner, with distinct colors for each method: green for de Bruijn, blue for Random Vars, and purple for Traditional.
---
### Components/Axes
- **Y-Axis**: Labeled "Accuracy (%)" with gridlines at 5% intervals (0, 5, 10, ..., 100).
- **X-Axis**: Labeled "Epochs" with gridlines at 10-epoch intervals (0, 10, 20, ..., 50).
- **Legend**: Located in the bottom-right corner, mapping:
- **Green**: de Bruijn
- **Blue**: Random Vars
- **Purple**: Traditional
---
### Detailed Analysis
#### de Bruijn (Green Line)
- **Initial Trend**: Starts at ~5% accuracy at epoch 0, rising sharply to ~50% by epoch 5.
- **Mid-Phase**: Fluctuates between ~55% and ~65% from epochs 5–20, stabilizing near ~60–65% by epoch 30.
- **Final Phase**: Slightly declines to ~65% by epoch 50, with minor oscillations.
#### Random Vars (Blue Line)
- **Initial Trend**: Begins at ~5% accuracy at epoch 0, rising to ~60% by epoch 5.
- **Mid-Phase**: Stabilizes between ~65% and ~70% from epochs 10–30, with minor dips.
- **Final Phase**: Peaks at ~70% by epoch 40, then fluctuates between ~65% and ~70% until epoch 50.
#### Traditional (Purple Line)
- **Initial Trend**: Starts at 0% accuracy at epoch 0, surging to ~70% by epoch 5.
- **Mid-Phase**: Peaks at ~85% by epoch 15, dips to ~75% at epoch 20, then rises to ~90% by epoch 30.
- **Final Phase**: Maintains ~90% accuracy with minor fluctuations (85–92%) until epoch 50.
---
### Key Observations
1. **Traditional Method Dominance**: Consistently achieves the highest accuracy, reaching ~90% by epoch 30 and maintaining it.
2. **de Bruijn vs. Random Vars**: Both methods plateau below 70%, with Random Vars slightly outperforming de Bruijn after epoch 10.
3. **Rapid Initial Growth**: All methods show steep accuracy gains in the first 5–10 epochs.
4. **Stability**: After epoch 20, all lines exhibit reduced volatility, suggesting convergence.
---
### Interpretation
The graph demonstrates that the **Traditional method** is the most effective for the task, achieving near-90% accuracy by epoch 30 and sustaining it. The **Random Vars** and **de Bruijn** methods lag behind, with Random Vars marginally outperforming de Bruijn in later epochs. The sharp initial rise in Traditional’s accuracy suggests it may leverage a more efficient learning mechanism or prior knowledge. The plateauing trends for de Bruijn and Random Vars imply diminishing returns after ~20 epochs, highlighting potential limitations in their scalability or adaptability. The data underscores the importance of method selection in optimization tasks, with Traditional emerging as the clear leader.