\n
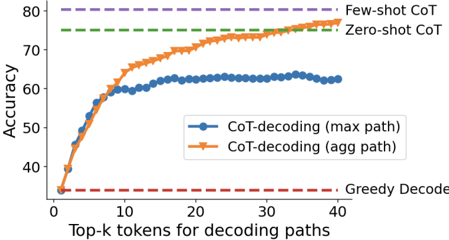
## Line Chart: Accuracy vs. Top-k Tokens for Decoding Paths
### Overview
The image is a line chart comparing the accuracy of different decoding methods as a function of the number of top-k tokens considered for decoding paths. It features two primary data series (CoT-decoding with max path and agg path) and three horizontal baseline reference lines.
### Components/Axes
* **X-Axis:** Labeled "Top-k tokens for decoding paths". The scale runs from 0 to 40, with major tick marks at intervals of 10 (0, 10, 20, 30, 40).
* **Y-Axis:** Labeled "Accuracy". The scale runs from approximately 30 to 80, with major tick marks at intervals of 10 (40, 50, 60, 70, 80).
* **Legend:** Located in the bottom-right quadrant of the chart area. It contains two entries:
1. A blue line with circle markers labeled "CoT-decoding (max path)".
2. An orange line with triangle markers labeled "CoT-decoding (agg path)".
* **Baseline Reference Lines (Dashed):**
* **Top (Purple):** A horizontal dashed line at approximately 80% accuracy, labeled "Few-shot CoT" on the right side.
* **Middle (Green):** A horizontal dashed line at approximately 75% accuracy, labeled "Zero-shot CoT" on the right side.
* **Bottom (Red):** A horizontal dashed line at approximately 35% accuracy, labeled "Greedy Decode" on the right side.
### Detailed Analysis
**Data Series Trends & Approximate Points:**
1. **CoT-decoding (max path) - Blue line with circles:**
* **Trend:** Shows a rapid initial increase in accuracy, which then plateaus. The curve rises steeply from k=1 to about k=10, after which the improvement becomes very marginal, forming a near-horizontal line from k=15 to k=40.
* **Approximate Data Points:**
* k=1: ~35%
* k=5: ~55%
* k=10: ~60%
* k=20: ~62%
* k=30: ~63%
* k=40: ~63%
2. **CoT-decoding (agg path) - Orange line with triangles:**
* **Trend:** Shows a continuous, strong upward trend across the entire range of k. The rate of improvement is steep initially and remains significant even at higher k values, approaching the "Few-shot CoT" baseline.
* **Approximate Data Points:**
* k=1: ~35%
* k=5: ~58%
* k=10: ~65%
* k=20: ~72%
* k=30: ~76%
* k=40: ~79%
**Baseline Comparisons:**
* Both CoT-decoding methods start near the "Greedy Decode" baseline (~35%) at k=1.
* The "agg path" method surpasses the "Zero-shot CoT" baseline (~75%) at approximately k=25.
* The "max path" method never reaches the "Zero-shot CoT" baseline, plateauing around 63%.
### Key Observations
1. **Performance Divergence:** The two CoT-decoding methods perform similarly for very low k (k=1-3) but diverge significantly as k increases. The "agg path" method demonstrates superior scalability.
2. **Plateau Effect:** The "max path" method exhibits a clear performance plateau after k≈15, suggesting that considering more decoding paths using this strategy yields diminishing returns.
3. **Baseline Relationship:** The "agg path" method's accuracy approaches the "Few-shot CoT" performance as k increases to 40, while the "max path" method remains well below the "Zero-shot CoT" baseline.
### Interpretation
The chart demonstrates the effectiveness of Chain-of-Thought (CoT) decoding strategies that aggregate information from multiple reasoning paths ("agg path") versus those that only consider the single highest-scoring path ("max path").
* **The "agg path" strategy is more robust and scalable.** Its continuous improvement with higher k suggests that aggregating evidence from numerous potential reasoning paths leads to more accurate final answers, effectively leveraging the increased computational budget (higher k).
* **The "max path" strategy has a limited ceiling.** Its rapid plateau indicates that simply picking the best individual path is insufficient for capturing the full benefit of exploring multiple reasoning chains. The model's performance is constrained by the quality of the single best path it can generate.
* **Practical Implication:** For tasks requiring complex reasoning, investing computational resources into exploring and aggregating multiple CoT paths (higher k with "agg path") is a more promising direction than refining the selection of a single path. The data suggests that with sufficient k, this approach can rival the performance of few-shot prompting, which typically requires carefully curated examples.