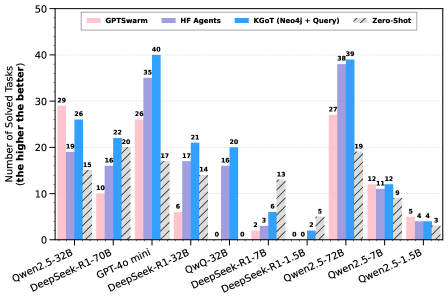
## Bar Chart: Number of Solved Tasks by Different Models
### Overview
The image is a bar chart comparing the performance of different language models on a set of tasks. The y-axis represents the number of solved tasks, with higher values indicating better performance. The x-axis represents different language models. The chart compares four different methods: GPTSwarm, HF Agents, KGOT (Neo4j + Query), and Zero-Shot.
### Components/Axes
* **Y-axis:** "Number of Solved Tasks (the higher the better)". The scale ranges from 0 to 50, with tick marks at intervals of 10.
* **X-axis:** Categorical axis representing different language models:
* Qwen2.5-32B
* DeepSeek-R1-70B
* GPT-4o mini
* DeepSeek-R1-32B
* QWQ-32B
* DeepSeek-R1-7B
* DeepSeek-R1-1.5B
* Qwen2.5-72B
* Qwen2.5-7B
* Qwen2.5-1.5B
* **Legend:** Located at the top-left of the chart.
* GPTSwarm (light pink)
* HF Agents (light purple)
* KGOT (Neo4j + Query) (blue)
* Zero-Shot (gray with diagonal lines)
### Detailed Analysis
Here's a breakdown of the number of solved tasks for each model and method:
* **Qwen2.5-32B:**
* GPTSwarm: 29
* HF Agents: 19
* KGOT (Neo4j + Query): 26
* Zero-Shot: 15
* **DeepSeek-R1-70B:**
* GPTSwarm: 10
* HF Agents: 16
* KGOT (Neo4j + Query): 22
* Zero-Shot: 0
* **GPT-4o mini:**
* GPTSwarm: 26
* HF Agents: 35
* KGOT (Neo4j + Query): 40
* Zero-Shot: 17
* **DeepSeek-R1-32B:**
* GPTSwarm: 6
* HF Agents: 17
* KGOT (Neo4j + Query): 21
* Zero-Shot: 14
* **QWQ-32B:**
* GPTSwarm: 0
* HF Agents: 16
* KGOT (Neo4j + Query): 20
* Zero-Shot: 0
* **DeepSeek-R1-7B:**
* GPTSwarm: 2
* HF Agents: 3
* KGOT (Neo4j + Query): 6
* Zero-Shot: 13
* **DeepSeek-R1-1.5B:**
* GPTSwarm: 0
* HF Agents: 0
* KGOT (Neo4j + Query): 2
* Zero-Shot: 0
* **Qwen2.5-72B:**
* GPTSwarm: 27
* HF Agents: 38
* KGOT (Neo4j + Query): 39
* Zero-Shot: 19
* **Qwen2.5-7B:**
* GPTSwarm: 11
* HF Agents: 12
* KGOT (Neo4j + Query): 12
* Zero-Shot: 9
* **Qwen2.5-1.5B:**
* GPTSwarm: 5
* HF Agents: 4
* KGOT (Neo4j + Query): 4
* Zero-Shot: 3
### Key Observations
* GPT-4o mini achieves the highest number of solved tasks using KGOT (Neo4j + Query) with a value of 40.
* Zero-Shot performance is generally lower than other methods across all models.
* The KGOT (Neo4j + Query) method consistently performs well across different models.
* DeepSeek-R1-1.5B performs poorly across all methods, with a maximum of 2 solved tasks.
### Interpretation
The chart provides a comparative analysis of different language models and methods for solving tasks. The KGOT (Neo4j + Query) method appears to be the most effective overall, as it consistently achieves high scores across different models. The Zero-Shot method generally underperforms compared to the other methods, suggesting that these models benefit from additional knowledge or prompting strategies. GPT-4o mini and Qwen2.5-72B show the best overall performance, indicating their effectiveness in solving the given tasks. The performance variations across different models and methods highlight the importance of selecting the appropriate model and strategy for specific tasks.