\n
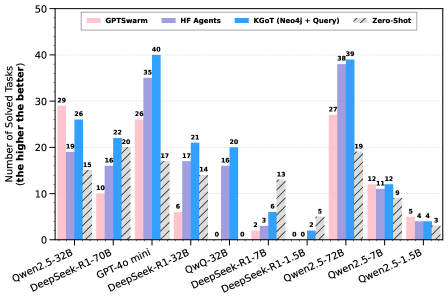
## Bar Chart: Performance Comparison of Different Agent Architectures
### Overview
This bar chart compares the performance of four different agent architectures – GPTswarm, HF Agents, KGoT (Neo4j + Query), and Zero-Shot – across a range of language models. The performance metric is the "Number of Solved Tasks" (the higher the better). The chart displays the number of solved tasks for each agent architecture on each language model.
### Components/Axes
* **X-axis:** Language Models - Owen2.5-32B, DeepSeek-R1-70B, GPT-40 mini, DeepSeek-R1-32B, QwQ-32B, DeepSeek-R1-7B, Owen2.5-72B, Owen2.5-7B, Owen2.5-1.5B
* **Y-axis:** Number of Solved Tasks (the higher the better), ranging from 0 to 50.
* **Legend:**
* GPTswarm (Light Red)
* HF Agents (Light Blue)
* KGoT (Neo4j + Query) (Medium Blue)
* Zero-Shot (Hatched Pattern)
### Detailed Analysis
The chart consists of a series of grouped bar plots, one group for each language model. For each model, there are four bars representing the performance of each agent architecture.
Here's a breakdown of the data, approximate values are provided with uncertainty due to bar height estimation:
* **Owen2.5-32B:**
* GPTswarm: ~19
* HF Agents: ~29
* KGoT: ~26
* Zero-Shot: ~3
* **DeepSeek-R1-70B:**
* GPTswarm: ~16
* HF Agents: ~26
* KGoT: ~17
* Zero-Shot: ~0
* **GPT-40 mini:**
* GPTswarm: ~22
* HF Agents: ~22
* KGoT: ~14
* Zero-Shot: ~0
* **DeepSeek-R1-32B:**
* GPTswarm: ~17
* HF Agents: ~40
* KGoT: ~21
* Zero-Shot: ~0
* **QwQ-32B:**
* GPTswarm: ~6
* HF Agents: ~16
* KGoT: ~14
* Zero-Shot: ~0
* **DeepSeek-R1-7B:**
* GPTswarm: ~20
* HF Agents: ~39
* KGoT: ~2
* Zero-Shot: ~0
* **Owen2.5-72B:**
* GPTswarm: ~27
* HF Agents: ~39
* KGoT: ~5
* Zero-Shot: ~2
* **Owen2.5-7B:**
* GPTswarm: ~19
* HF Agents: ~37
* KGoT: ~12
* Zero-Shot: ~3
* **Owen2.5-1.5B:**
* GPTswarm: ~12
* HF Agents: ~19
* KGoT: ~9
* Zero-Shot: ~4
**Trends:**
* **HF Agents** consistently outperforms the other architectures across most language models, generally achieving the highest number of solved tasks. The HF Agents line generally slopes upward, peaking at Owen2.5-72B and DeepSeek-R1-7B.
* **GPTswarm** shows moderate performance, generally falling between HF Agents and KGoT.
* **KGoT** generally performs the worst, with very low scores on several models.
* **Zero-Shot** consistently has the lowest performance, often scoring 0 solved tasks.
### Key Observations
* HF Agents demonstrate a clear advantage over other architectures.
* The performance of all architectures varies significantly depending on the language model used.
* Zero-Shot consistently underperforms, suggesting it is not a viable approach for these tasks.
* DeepSeek-R1-32B shows the highest performance for HF Agents, reaching 40 solved tasks.
### Interpretation
The data suggests that HF Agents are the most effective architecture for solving tasks using these language models. The significant difference in performance between HF Agents and other architectures highlights the benefits of the HF Agents approach. The variation in performance across different language models indicates that the choice of language model is crucial for achieving good results. The consistently poor performance of Zero-Shot suggests that it lacks the necessary capabilities for these tasks. The chart provides valuable insights into the strengths and weaknesses of different agent architectures and can inform the selection of the most appropriate architecture for a given task and language model. The high performance of HF Agents on DeepSeek-R1-32B is a notable outlier, suggesting a particularly strong synergy between these two components.