## Bar Charts: Brain Alignment Comparison
### Overview
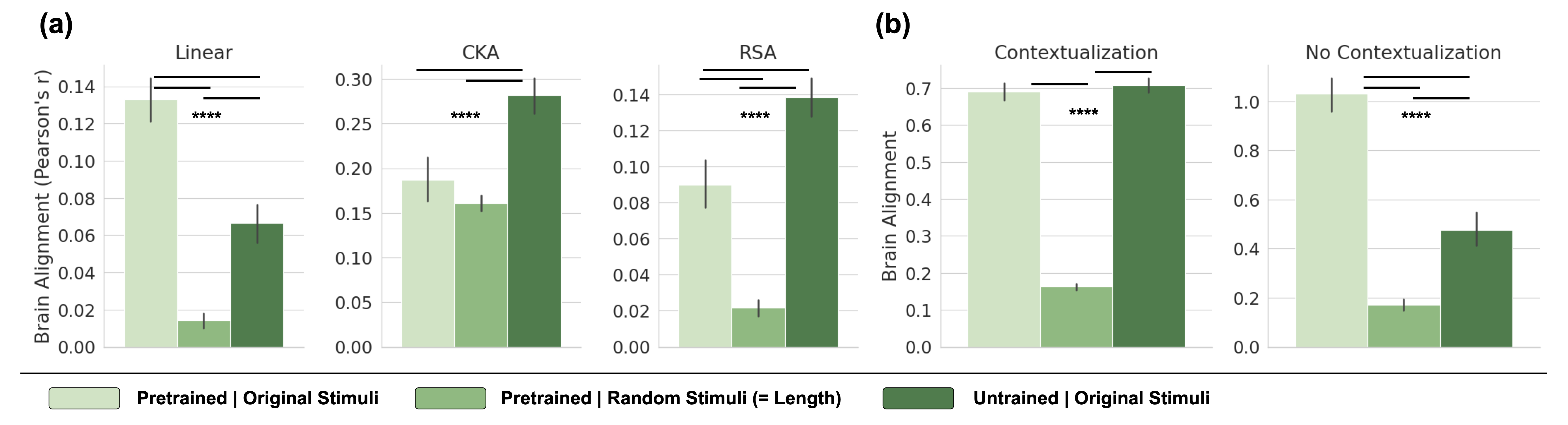
The image presents two sets of bar charts, (a) and (b), comparing brain alignment under different conditions. The x-axis represents different experimental setups (Linear, CKA, RSA, Contextualization, No Contextualization), while the y-axis represents brain alignment scores. The charts compare "Pretrained | Original Stimuli", "Pretrained | Random Stimuli (= Length)", and "Untrained | Original Stimuli". Statistical significance is indicated by asterisks above the bars.
### Components/Axes
**Chart (a):**
* **Title:** Linear, CKA, RSA
* **Y-axis Title:** Brain Alignment (Pearson's r)
* **Y-axis Scale:** 0.00 to 0.14 (Linear, RSA), 0.00 to 0.30 (CKA), incrementing by 0.02 (Linear, RSA) and 0.05 (CKA)
* **X-axis:** Categorical, representing different experimental setups: Linear, CKA, RSA
* **Legend (bottom):**
* Light Green: Pretrained | Original Stimuli
* Medium Green: Pretrained | Random Stimuli (= Length)
* Dark Green: Untrained | Original Stimuli
**Chart (b):**
* **Title:** Contextualization, No Contextualization
* **Y-axis Title:** Brain Alignment
* **Y-axis Scale:** 0.0 to 0.7 (Contextualization), 0.0 to 1.0 (No Contextualization), incrementing by 0.1
* **X-axis:** Categorical, representing different experimental setups: Contextualization, No Contextualization
* **Legend (bottom):** Same as Chart (a)
### Detailed Analysis
**Chart (a):**
* **Linear:**
* Pretrained | Original Stimuli (Light Green): ~0.13, with error bar extending to ~0.14
* Pretrained | Random Stimuli (= Length) (Medium Green): ~0.01, with error bar extending to ~0.02
* Untrained | Original Stimuli (Dark Green): ~0.07, with error bar extending to ~0.08
* **CKA:**
* Pretrained | Original Stimuli (Light Green): ~0.19, with error bar extending to ~0.21
* Pretrained | Random Stimuli (= Length) (Medium Green): ~0.16, with error bar extending to ~0.17
* Untrained | Original Stimuli (Dark Green): ~0.28, with error bar extending to ~0.30
* **RSA:**
* Pretrained | Original Stimuli (Light Green): ~0.09, with error bar extending to ~0.10
* Pretrained | Random Stimuli (= Length) (Medium Green): ~0.02, with error bar extending to ~0.03
* Untrained | Original Stimuli (Dark Green): ~0.14, with error bar extending to ~0.15
**Chart (b):**
* **Contextualization:**
* Pretrained | Original Stimuli (Light Green): ~0.69, with error bar extending to ~0.71
* Pretrained | Random Stimuli (= Length) (Medium Green): ~0.16, with error bar extending to ~0.17
* Untrained | Original Stimuli (Dark Green): ~0.70, with error bar extending to ~0.72
* **No Contextualization:**
* Pretrained | Original Stimuli (Light Green): ~1.01, with error bar extending to ~1.03
* Pretrained | Random Stimuli (= Length) (Medium Green): ~0.17, with error bar extending to ~0.18
* Untrained | Original Stimuli (Dark Green): ~0.47, with error bar extending to ~0.49
### Key Observations
* In Chart (a), for Linear and RSA, "Pretrained | Original Stimuli" shows the highest brain alignment, while "Pretrained | Random Stimuli (= Length)" shows the lowest. For CKA, "Untrained | Original Stimuli" shows the highest brain alignment.
* In Chart (b), for both Contextualization and No Contextualization, "Pretrained | Original Stimuli" shows the highest brain alignment, while "Pretrained | Random Stimuli (= Length)" shows the lowest.
* Statistical significance (****) is indicated above the bars in all sub-charts, suggesting significant differences between the groups being compared.
### Interpretation
The data suggests that brain alignment varies significantly depending on the experimental setup (Linear, CKA, RSA, Contextualization, No Contextualization) and the type of stimuli used (Original vs. Random) in both pretrained and untrained models. The high brain alignment observed with "Pretrained | Original Stimuli" in most cases indicates that pretraining on original stimuli leads to better alignment with brain activity. The lower alignment with "Pretrained | Random Stimuli (= Length)" suggests that random stimuli, even when matched in length, do not elicit the same level of brain alignment as original stimuli. The performance of "Untrained | Original Stimuli" varies, sometimes showing comparable alignment to pretrained models (e.g., Contextualization) and sometimes showing lower alignment (e.g., Linear, RSA). The statistical significance (****) highlights that these differences are not due to random chance, but rather reflect genuine effects of the experimental manipulations.