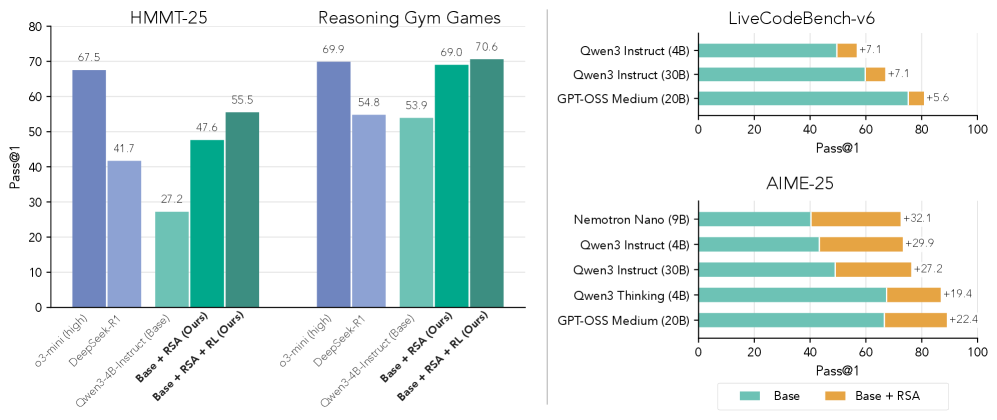
# Technical Data Extraction: Model Performance Comparison
This document provides a comprehensive extraction of data from a composite technical chart comparing various Large Language Models (LLMs) across four benchmarks: **HMMT-25**, **Reasoning Gym Games**, **LiveCodeBench-v6**, and **AIME-25**.
---
## 1. Left Panel: Vertical Bar Charts (HMMT-25 & Reasoning Gym Games)
This section contains two grouped bar charts sharing a common Y-axis.
### Metadata
* **Y-Axis Label:** Pass@1
* **Y-Axis Scale:** 0 to 80 (increments of 10)
* **X-Axis Categories (Models):**
1. o3-mini (high) [Color: Dark Blue/Purple]
2. DeepSeek-R1 [Color: Light Blue/Purple]
3. Qwen3-4B-Instruct (Base) [Color: Light Teal]
4. Base + RSA (Ours) [Color: Medium Teal]
5. Base + RSA + RL (Ours) [Color: Dark Teal]
### Data Table: HMMT-25
| Model | Pass@1 Value |
| :--- | :--- |
| o3-mini (high) | 67.5 |
| DeepSeek-R1 | 41.7 |
| Qwen3-4B-Instruct (Base) | 27.2 |
| Base + RSA (Ours) | 47.6 |
| Base + RSA + RL (Ours) | 55.5 |
**Trend Analysis:** In the HMMT-25 benchmark, the "Ours" methodology shows significant incremental improvement over the Base Qwen3-4B-Instruct model. Adding RSA increases performance by 20.4 points, and adding RL further increases it by 7.9 points. It outperforms DeepSeek-R1 but remains below o3-mini (high).
### Data Table: Reasoning Gym Games
| Model | Pass@1 Value |
| :--- | :--- |
| o3-mini (high) | 69.9 |
| DeepSeek-R1 | 54.8 |
| Qwen3-4B-Instruct (Base) | 53.9 |
| Base + RSA (Ours) | 69.0 |
| Base + RSA + RL (Ours) | 70.6 |
**Trend Analysis:** In Reasoning Gym Games, the "Base + RSA + RL" configuration achieves the highest score in the set (70.6), slightly surpassing o3-mini (high). The RSA component provides a substantial jump (+15.1) from the base model.
---
## 2. Right Panel: Horizontal Stacked Bar Charts
This section compares "Base" performance against "Base + RSA" performance across different model architectures.
### Legend
* **Teal Bar:** Base
* **Orange Bar:** Base + RSA (The value shown is the improvement or delta over the base)
### Chart: LiveCodeBench-v6
* **X-Axis:** Pass@1 (Scale 0 to 100, increments of 20)
| Model | Base Score | RSA Improvement (Delta) | Total Score (Visual) |
| :--- | :--- | :--- | :--- |
| Qwen3 Instruct (4B) | ~50 | +7.1 | ~57.1 |
| Qwen3 Instruct (30B) | ~60 | +7.1 | ~67.1 |
| GPT-OSS Medium (20B) | ~75 | +5.6 | ~80.6 |
**Trend Analysis:** RSA provides a consistent positive delta across different model sizes and families in coding tasks, with a slightly higher impact on smaller Qwen models compared to the larger GPT-OSS model.
### Chart: AIME-25
* **X-Axis:** Pass@1 (Scale 0 to 100, increments of 20)
| Model | Base Score | RSA Improvement (Delta) | Total Score (Visual) |
| :--- | :--- | :--- | :--- |
| Nemotron Nano (9B) | ~40 | +32.1 | ~72.1 |
| Qwen3 Instruct (4B) | ~43 | +29.9 | ~72.9 |
| Qwen3 Instruct (30B) | ~49 | +27.2 | ~76.2 |
| Qwen3 Thinking (4B) | ~67 | +19.4 | ~86.4 |
| GPT-OSS Medium (20B) | ~66 | +22.4 | ~88.4 |
**Trend Analysis:** The impact of RSA is most dramatic in the AIME-25 (mathematics) benchmark. The deltas are significantly larger than in the coding benchmark, often increasing the base performance by over 50% (e.g., Nemotron Nano jumping from ~40 to ~72).
---
## Summary of Findings
The data indicates that the "RSA" (Reasoning-Step Alignment/Augmentation) and "RL" (Reinforcement Learning) interventions consistently improve performance across all tested benchmarks. The most significant gains are observed in mathematical reasoning (AIME-25), where the RSA component adds between 19.4 and 32.1 points to the base Pass@1 score. In general reasoning (Reasoning Gym), the optimized 4B model (70.6) is shown to be competitive with or superior to much larger or specialized models like o3-mini and DeepSeek-R1.