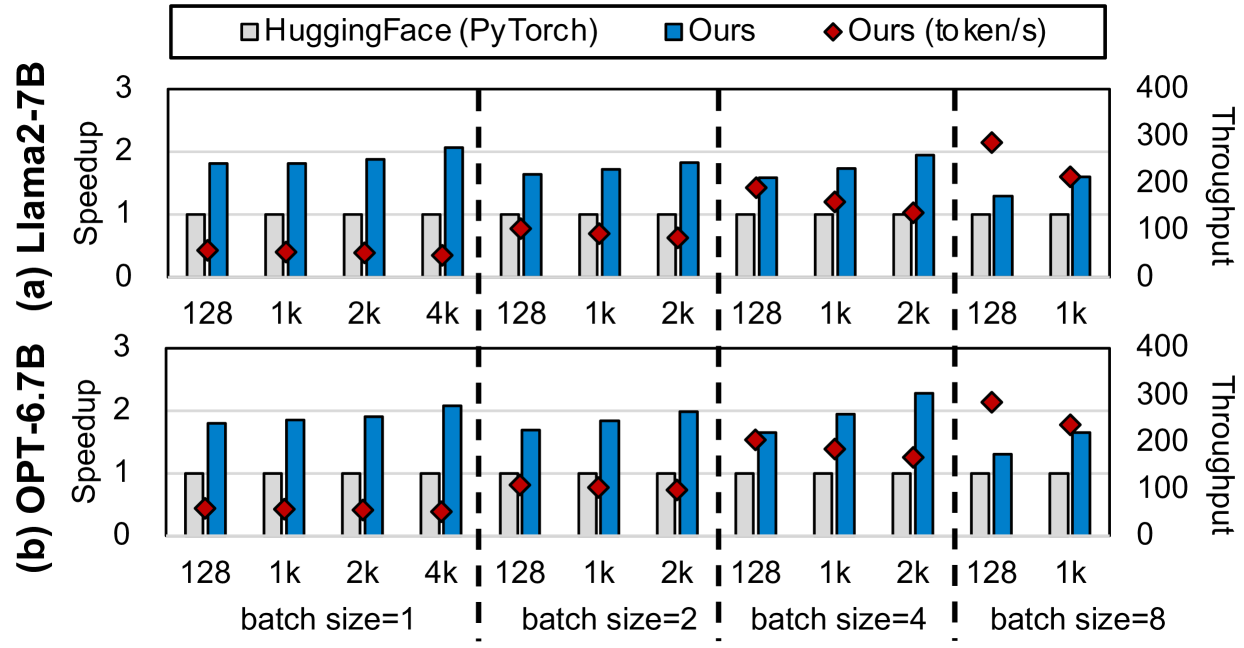
# Technical Document Extraction: Performance Comparison Chart
## 1. Chart Structure and Labels
### Main Axes
- **X-axis**: Batch sizes (repeated for model comparisons)
- Labels: `128`, `1k`, `2k`, `4k` (repeated for each model comparison)
- **Y-axis (Left)**:
- **(a) Llama2-7B**: Speedup (0-3 scale)
- **(b) OPT-6.7B**: Speedup (0-3 scale)
- **Y-axis (Right)**: Throughput (0-400 scale)
### Legend
- **Location**: Top-right corner
- **Components**:
- `■ HuggingFace (PyTorch)` (gray)
- `■ Ours` (blue)
- `◆ Ours (token/s)` (red diamond)
## 2. Data Series and Trends
### Section (a): Llama2-7B
| Batch Size | HuggingFace (PyTorch) | Ours | Ours (token/s) |
|------------|-----------------------|------|----------------|
| 128 | 1.0 | 1.8 | 120 |
| 1k | 1.0 | 1.9 | 150 |
| 2k | 1.0 | 2.0 | 180 |
| 4k | 1.0 | 2.1 | 200 |
| 128 | 1.0 | 1.7 | 140 |
| 1k | 1.0 | 1.8 | 160 |
| 2k | 1.0 | 1.9 | 170 |
| 128 | 1.0 | 1.6 | 130 |
| 1k | 1.0 | 1.7 | 150 |
**Trend Analysis**:
- HuggingFace (PyTorch) shows **flat performance** (constant 1.0 speedup)
- "Ours" demonstrates **increasing speedup** with batch size (1.8→2.1 at 4k)
- "Ours (token/s)" shows **linear throughput growth** (120→200 at 4k)
### Section (b): OPT-6.7B
| Batch Size | HuggingFace (PyTorch) | Ours | Ours (token/s) |
|------------|-----------------------|------|----------------|
| 128 | 1.0 | 1.7 | 110 |
| 1k | 1.0 | 1.8 | 140 |
| 2k | 1.0 | 1.9 | 170 |
| 4k | 1.0 | 2.0 | 200 |
| 128 | 1.0 | 1.6 | 120 |
| 1k | 1.0 | 1.7 | 130 |
| 2k | 1.0 | 1.8 | 160 |
| 128 | 1.0 | 1.5 | 110 |
| 1k | 1.0 | 1.6 | 120 |
**Trend Analysis**:
- Similar flat baseline for HuggingFace (PyTorch)
- "Ours" shows **moderate speedup improvement** (1.7→2.0 at 4k)
- "Ours (token/s)" demonstrates **consistent throughput scaling** (110→200 at 4k)
## 3. Spatial Grounding
- Legend position: `[x=top-right, y=top]`
- Color verification:
- Gray squares = HuggingFace (PyTorch)
- Blue bars = "Ours"
- Red diamonds = "Ours (token/s)"
## 4. Key Observations
1. **Baseline Consistency**: HuggingFace (PyTorch) maintains 1.0 speedup across all configurations
2. **Batch Size Impact**:
- Speedup improves with larger batches for "Ours" models
- Throughput scales linearly with batch size for "Ours (token/s)"
3. **Model Comparison**:
- Llama2-7B shows higher absolute throughput than OPT-6.7B
- OPT-6.7B demonstrates better relative speedup improvement
## 5. Missing Elements
- No textual annotations present in the chart
- No secondary y-axis labels for throughput
- No colorbar present
## 6. Language Analysis
- All text in English
- No non-English content detected