\n
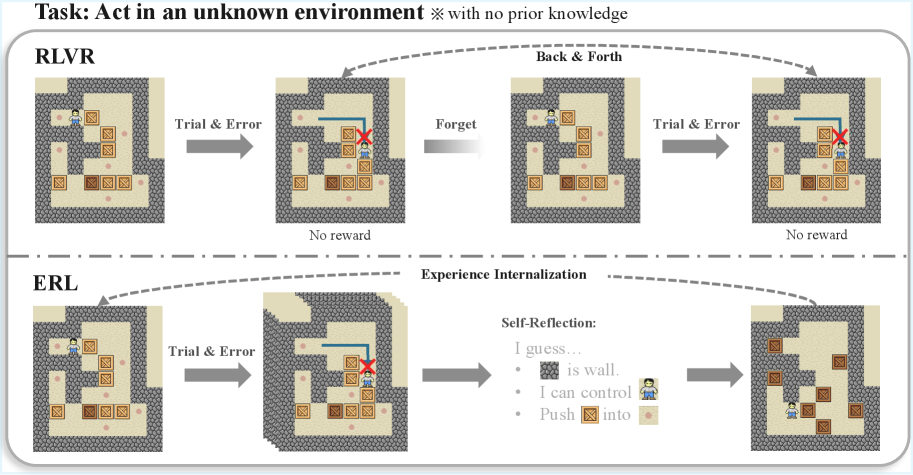
## Diagram: RLVR vs. ERL - Acting in an Unknown Environment
### Overview
This diagram illustrates a comparison between two reinforcement learning approaches, RLVR (Reinforcement Learning with Value Rewriting) and ERL (Experience Replay with Learning), when tasked with navigating an agent in an unknown environment without prior knowledge. The diagram depicts the agent's progression through a maze-like environment, highlighting the differences in how each approach handles trial and error, memory, and learning.
### Components/Axes
The diagram is divided into two main sections, one for RLVR and one for ERL, separated by a dashed line. Each section shows a sequence of four maze snapshots, connected by arrows indicating the progression of the agent's actions. Labels are present above each section ("RLVR", "ERL") and descriptive text accompanies each step. The overall task is stated at the top: "Task: Act in an unknown environment ※ with no prior knowledge". The connecting arrows are labeled "Back & Forth" (above RLVR) and "Experience Internalization" (above ERL).
### Detailed Analysis or Content Details
**RLVR Section:**
* **Snapshot 1:** An agent (blue figure) is positioned in a maze with several boxes (brown squares) and goal locations (yellow squares).
* Label: "Trial & Error"
* **Snapshot 2:** The agent attempts to move through a wall (grey blocks), resulting in no reward. A red 'X' marks the attempted invalid move.
* Label: "No reward"
* **Snapshot 3:** The agent's previous attempt is "forgotten". The maze is reset to the initial state.
* Label: "Forget"
* **Snapshot 4:** The agent again attempts to navigate the maze, this time successfully pushing a box onto a goal location. A red 'X' marks the attempted invalid move.
* Label: "Trial & Error"
* Label: "No reward"
**ERL Section:**
* **Snapshot 1:** The agent is positioned in the same maze as in the RLVR section.
* Label: "Trial & Error"
* **Snapshot 2:** The agent attempts to move through a wall, resulting in no reward. A red 'X' marks the attempted invalid move.
* Label: "No reward"
* **Snapshot 3:** A "Self-Reflection" box appears, containing the following text:
* "I guess…"
* "🧱 is wall."
* "I can control"
* "Push 📦 into 🟡"
* **Snapshot 4:** The agent successfully pushes a box onto a goal location.
* No label.
**Maze Details (Common to both sections):**
The maze consists of walls (grey blocks), empty spaces (beige), boxes (brown squares), and goal locations (yellow squares). The agent is represented by a blue figure.
### Key Observations
The key difference between RLVR and ERL is how they handle unsuccessful attempts. RLVR simply "forgets" the failed attempt and restarts, while ERL engages in "self-reflection" to learn from the experience, explicitly identifying the wall as an obstacle and the ability to manipulate boxes. Both approaches start with "Trial & Error", but diverge in their subsequent processing of that experience.
### Interpretation
The diagram demonstrates a conceptual difference in how reinforcement learning agents can learn. RLVR represents a more basic approach where learning is purely through repeated trial and error without explicit memory or reasoning. ERL, on the other hand, incorporates a form of internal representation and reasoning ("self-reflection") to improve learning efficiency. The "self-reflection" step suggests that ERL is capable of abstracting knowledge from its experiences (e.g., recognizing "🧱 is wall") and using that knowledge to guide future actions. This highlights the potential benefits of incorporating cognitive mechanisms, such as reasoning and memory, into reinforcement learning algorithms. The diagram suggests that ERL is more likely to succeed in complex environments because it doesn't simply repeat mistakes but learns from them. The use of the "※" symbol next to "no prior knowledge" emphasizes the importance of learning from scratch in an unknown environment.