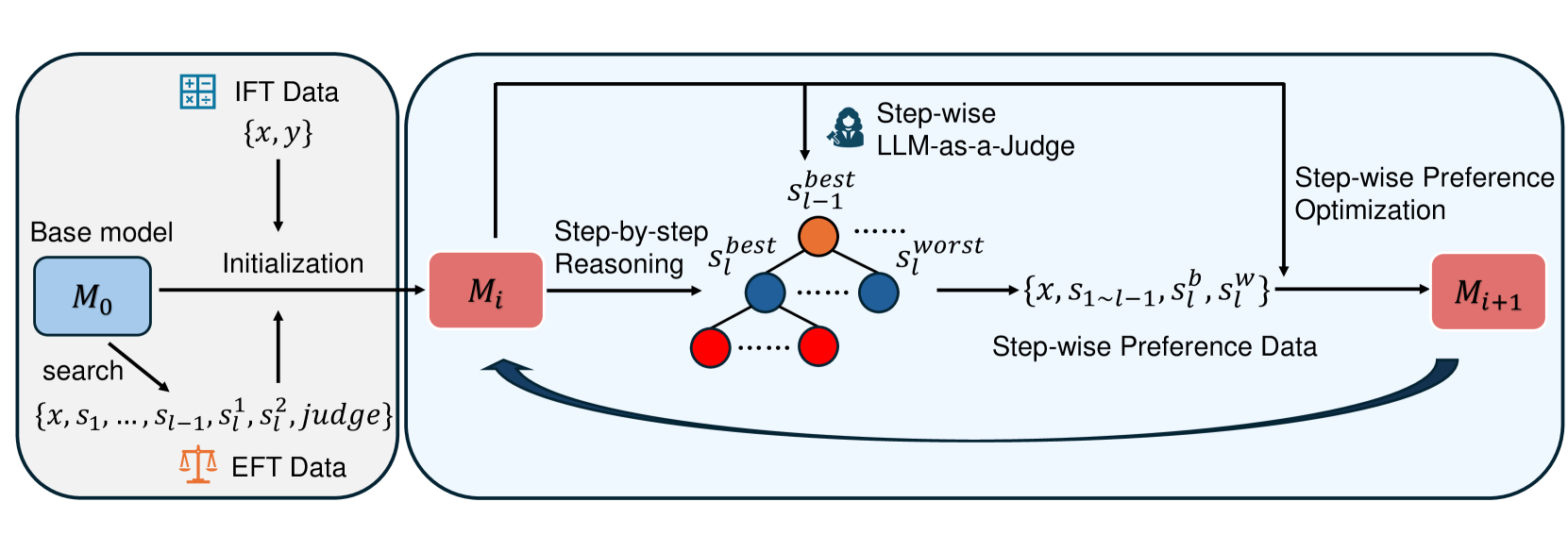
## Diagram: Iterative Fine-Tuning Process
### Overview
The image is a diagram illustrating an iterative fine-tuning process for a base model using IFT (Instruction Fine-Tuning) and EFT (Evaluation Fine-Tuning) data. The process involves initializing a base model, step-by-step reasoning, preference evaluation using an LLM (Large Language Model), and optimization based on preference data.
### Components/Axes
* **IFT Data**: Represented by a grid icon and the set `{x, y}`. Located at the top-left.
* **Base model**: Represented by a blue rounded rectangle labeled "M₀". Located at the left.
* **Initialization**: Text label indicating the process of initializing the base model with IFT data.
* **EFT Data**: Represented by a scale icon and the set `{x, s₁, ..., sₗ₋₁, s¹ₗ, s²ₗ, judge}`. Located at the bottom-left.
* **Step-by-step Reasoning**: Text label indicating the process of step-by-step reasoning.
* **LLM-as-a-Judge**: Text label indicating the use of a Large Language Model as a judge. Includes a female silhouette icon.
* **Step-wise Preference Optimization**: Text label indicating the process of step-wise preference optimization.
* **Mᵢ**: Represented by a red rounded rectangle.
* **Mᵢ₊₁**: Represented by a red rounded rectangle.
* **s best ₗ₋₁**: Orange circle at the top of a tree structure.
* **s best ₗ**: Blue circles in the tree structure.
* **s worst ₗ**: Text label indicating the worst score.
* **{x, s₁~ₗ₋₁, sᵇₗ, sʷₗ}**: Set of data used for step-wise preference data.
* **Step-wise Preference Data**: Text label indicating the data used for preference optimization.
### Detailed Analysis or Content Details
1. **Initialization Phase**:
* The base model "M₀" (blue rounded rectangle) is initialized using "IFT Data" `{x, y}`.
* "EFT Data" `{x, s₁, ..., sₗ₋₁, s¹ₗ, s²ₗ, judge}` is used in a search process to refine the model.
2. **Iterative Fine-Tuning Loop**:
* The model "M₀" transitions to "Mᵢ" (red rounded rectangle) through an initialization process.
* "Mᵢ" undergoes "Step-by-step Reasoning".
* An "LLM-as-a-Judge" evaluates the reasoning steps, generating a tree structure with nodes representing different states. The top node is labeled "s best ₗ₋₁" (orange circle). Subsequent nodes are labeled "s best ₗ" (blue circles), and the worst score is labeled "s worst ₗ".
* The output of the LLM-as-a-Judge is the set `{x, s₁~ₗ₋₁, sᵇₗ, sʷₗ}`, which represents "Step-wise Preference Data".
* "Step-wise Preference Optimization" is applied to update the model from "Mᵢ" to "Mᵢ₊₁" (red rounded rectangle).
* A curved arrow indicates a loop, suggesting that "Mᵢ₊₁" becomes the new "Mᵢ" for the next iteration.
### Key Observations
* The diagram illustrates a closed-loop iterative process.
* The LLM-as-a-Judge component plays a crucial role in evaluating and guiding the fine-tuning process.
* The use of both IFT and EFT data suggests a comprehensive approach to model refinement.
### Interpretation
The diagram presents a method for iteratively fine-tuning a base model using a combination of instruction fine-tuning data (IFT) and evaluation fine-tuning data (EFT). The core idea is to leverage a large language model (LLM) as a judge to evaluate the step-by-step reasoning of the model and generate preference data. This preference data is then used to optimize the model in each iteration. The iterative nature of the process allows for continuous improvement of the model's performance. The tree structure visually represents the decision-making process of the LLM-as-a-Judge, where different reasoning paths are evaluated, and the best and worst states are identified. This approach aims to improve the model's reasoning capabilities and overall performance by incorporating human-like judgment into the fine-tuning process.