\n
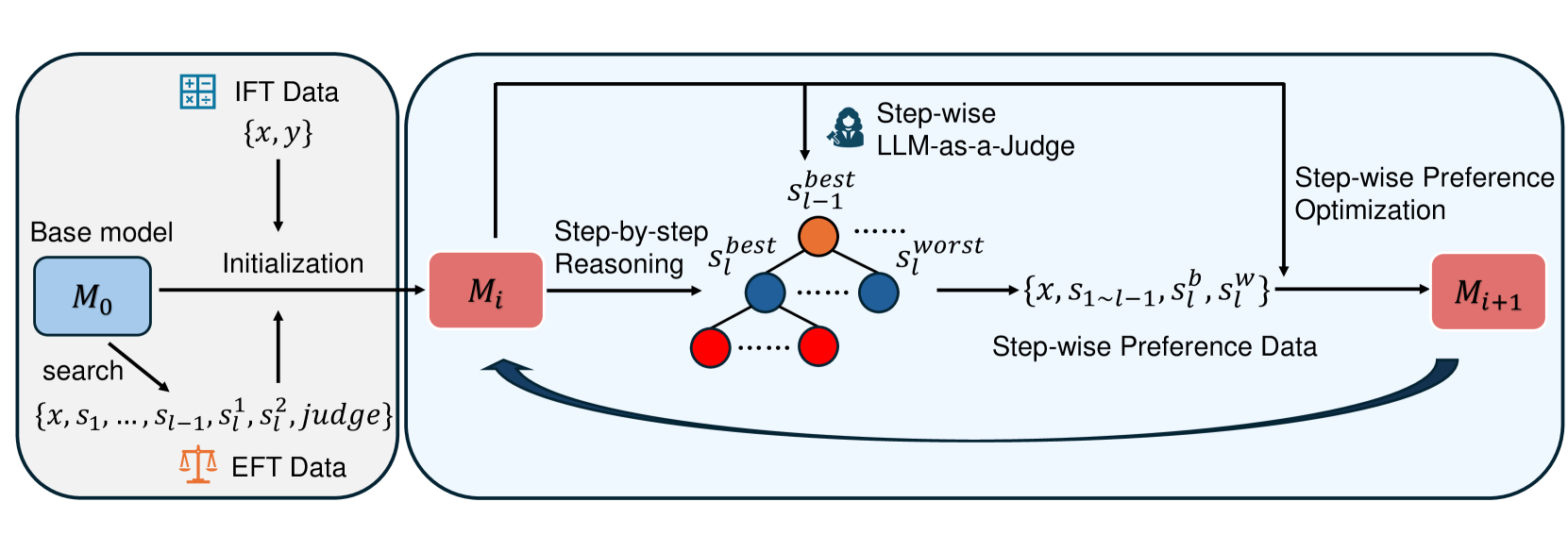
## Diagram: Step-wise Preference Optimization Process
### Overview
This diagram illustrates a process for iteratively improving a base model (M₀) through step-wise preference optimization, utilizing both IFT (Instruction Following Tuning) and EFT (Explanation Following Tuning) data. The process involves reasoning, judging, and updating the model based on preferences.
### Components/Axes
The diagram consists of three main rectangular blocks representing stages in the process, connected by arrows indicating flow. Key components include:
* **Base Model (M₀, Mᵢ, Mᵢ₊₁):** Represented by rounded rectangles, these denote the model at different stages of optimization.
* **IFT Data:** Represented by a checkered box, labeled "{x, y}".
* **EFT Data:** Represented by an orange box, labeled "{x, S₁…S₁₋₁, S¹, S², judge}".
* **Step-by-step Reasoning:** A central block with red circles representing steps, labeled "Sₜbest" to "Sₜworst".
* **LLM-as-a-Judge:** A head icon within the "Step-by-step Reasoning" block.
* **Step-wise Preference Data:** A rectangular box labeled "{x, S₁…S₁₋₁, S¹, S², Sʷ}".
* **Step-wise Preference Optimization:** A rectangular block.
* **Initialization:** An arrow connecting IFT Data to the Base Model (M₀).
* **Search:** An arrow connecting EFT Data to the Base Model (M₀).
### Detailed Analysis or Content Details
The process begins with a Base Model (M₀).
1. **Initialization:** The model is initialized using IFT Data, represented as "{x, y}". The arrow indicates data flows *into* the Base Model.
2. **Search:** Simultaneously, the model is also initialized using EFT Data, represented as "{x, S₁…S₁₋₁, S¹, S², judge}". The arrow indicates data flows *into* the Base Model.
3. **Step-by-step Reasoning:** The current model (Mᵢ) undergoes step-by-step reasoning, visualized as a series of red circles labeled from "Sₜbest" to "Sₜworst". This suggests a ranking or ordering of steps.
4. **LLM-as-a-Judge:** A Large Language Model (LLM) acts as a judge within the reasoning process.
5. **Step-wise Preference Data:** The output of the reasoning process is Step-wise Preference Data, represented as "{x, S₁…S₁₋₁, S¹, S², Sʷ}".
6. **Step-wise Preference Optimization:** This data is then used in a Step-wise Preference Optimization process.
7. **Model Update:** The optimization process results in an updated model (Mᵢ₊₁).
8. **Iterative Loop:** A curved arrow indicates a feedback loop, where the updated model (Mᵢ₊₁) is used to generate new EFT Data, continuing the iterative process.
### Key Observations
The diagram highlights an iterative process where the model is continuously refined based on preference data. The use of both IFT and EFT data suggests a combined approach to learning. The LLM-as-a-Judge component indicates a reliance on a language model for evaluating the quality of reasoning steps. The iterative loop suggests a continuous improvement cycle.
### Interpretation
This diagram describes a reinforcement learning from human feedback (RLHF) or similar iterative optimization process for language models. The IFT data likely provides initial instruction-following capabilities, while the EFT data focuses on refining the model's reasoning process based on explanations and preferences. The LLM acting as a judge is crucial for evaluating the quality of different reasoning paths. The iterative loop suggests that the model's performance is expected to improve over time as it receives more feedback and refines its reasoning abilities. The use of "best" and "worst" labels on the reasoning steps indicates a preference ranking, which is used to guide the optimization process. The diagram emphasizes the importance of both instruction following and reasoning in building high-performing language models. The EFT data is used to refine the model, and the iterative loop suggests a continuous learning process. The diagram does not provide specific numerical data or performance metrics, but rather illustrates the overall process flow.