TECHNICAL ASSET FINGERPRINT
abb2876e971d780ad6451af0
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
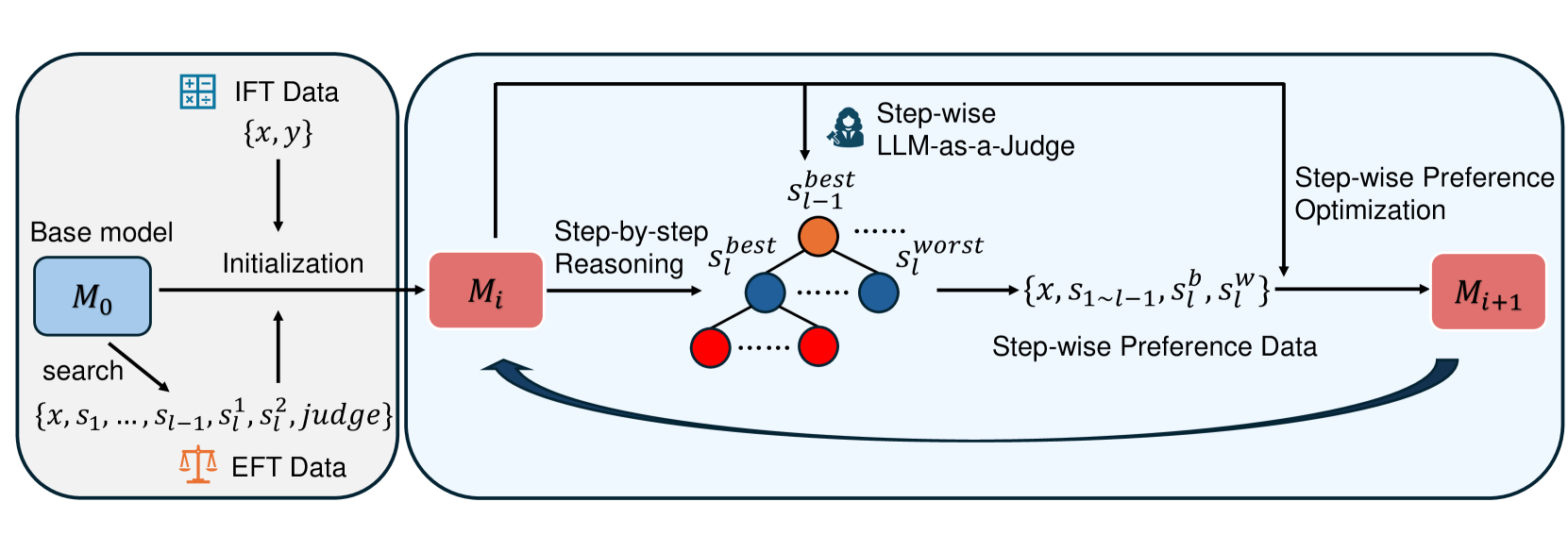
## Diagram: Step-wise Preference Optimization Training Pipeline
### Overview
This image is a technical flowchart illustrating a machine learning training pipeline. The process involves initializing a model and then iteratively improving it through step-wise reasoning, evaluation, and preference optimization. The diagram is divided into two main sections: an "Initialization" phase on the left and an iterative training loop on the right.
### Components/Axes
The diagram is composed of labeled boxes, text, mathematical notation, icons, and directional arrows indicating data and process flow.
**Left Section: Initialization**
* **Box Label:** "Initialization" (centered within a rounded rectangle).
* **Components:**
* **Base model:** A blue box labeled `M₀`.
* **IFT Data:** An icon of a calculator with the text "IFT Data" and the notation `{x, y}`. An arrow points from this data to the "Initialization" process.
* **EFT Data:** An icon of a balance scale with the text "EFT Data" and the notation `{x, s₁, ..., s_{l-1}, s_l¹, s_l², judge}`. An arrow labeled "search" points from `M₀` to this data, and another arrow points from this data to the "Initialization" process.
* **Flow:** Arrows from `M₀`, IFT Data, and EFT Data converge into the "Initialization" process. A single arrow exits this section, pointing to the model `Mᵢ` in the right section.
**Right Section: Iterative Training Loop**
* **Central Model:** A red box labeled `Mᵢ`.
* **Process Flow (Step-by-step):**
1. **Step-by-step Reasoning:** An arrow from `Mᵢ` points to a tree structure. The text "Step-by-step Reasoning" is above this arrow.
2. **Tree Structure:** Represents reasoning steps.
* The root node is orange and labeled `s_{l-1}^{best}`.
* It branches to two child nodes: a blue node labeled `s_l^{best}` and a red node labeled `s_l^{worst}`.
* Ellipses (`...`) indicate additional nodes at each level.
* The blue `s_l^{best}` node further branches to two red child nodes, with ellipses indicating more.
3. **Evaluation:** An icon of a person with a magnifying glass, labeled "Step-wise LLM-as-a-Judge", points to the orange root node (`s_{l-1}^{best}`) of the tree.
4. **Data Generation:** An arrow exits the tree structure, pointing to the notation `{x, s_{1~l-1}, s_l^b, s_l^w}`. Below this is the label "Step-wise Preference Data".
5. **Optimization:** An arrow from the preference data points to the text "Step-wise Preference Optimization".
6. **Model Update:** An arrow from "Step-wise Preference Optimization" points to a new red box labeled `M_{i+1}`.
* **Feedback Loop:** A large, curved arrow points from `M_{i+1}` back to `Mᵢ`, indicating the iterative nature of the process.
### Detailed Analysis
**Textual and Notational Transcription:**
* **Initialization Phase:**
* `M₀` (Base model)
* IFT Data: `{x, y}`
* EFT Data: `{x, s₁, ..., s_{l-1}, s_l¹, s_l², judge}`
* Labels: "Base model", "search", "Initialization", "IFT Data", "EFT Data".
* **Iterative Loop Phase:**
* `Mᵢ` (Current model)
* Tree Nodes: `s_{l-1}^{best}` (orange), `s_l^{best}` (blue), `s_l^{worst}` (red).
* Preference Data Notation: `{x, s_{1~l-1}, s_l^b, s_l^w}`.
* `M_{i+1}` (Updated model)
* Labels: "Step-by-step Reasoning", "Step-wise LLM-as-a-Judge", "Step-wise Preference Data", "Step-wise Preference Optimization".
**Spatial Grounding & Component Isolation:**
* **Header/Top:** Contains the "Step-wise LLM-as-a-Judge" icon and label, positioned above the central tree structure.
* **Main Chart/Center:** The core process flow from `Mᵢ` through the reasoning tree to `M_{i+1}`.
* **Footer/Bottom:** The large feedback arrow connecting `M_{i+1}` back to `Mᵢ`.
* **Legend/Color Code:** Colors are used semantically:
* **Blue:** Associated with the base model (`M₀`) and the "best" reasoning step (`s_l^{best}`).
* **Red:** Associated with the current/updated models (`Mᵢ`, `M_{i+1}`) and the "worst" reasoning step (`s_l^{worst}`).
* **Orange:** Highlights the current best step (`s_{l-1}^{best}`) being judged.
### Key Observations
1. **Two Data Types:** The initialization uses two distinct datasets: IFT (likely Instruction Fine-Tuning) Data with input-output pairs `{x, y}`, and EFT (likely Exploration/Experiential Fine-Tuning) Data which includes intermediate reasoning steps (`s`) and a `judge` signal.
2. **Step-wise Granularity:** The core innovation is evaluating and optimizing at the level of individual reasoning steps (`s_l`), not just the final output. The tree visualizes exploring multiple step options (`s_l¹, s_l²`, etc.).
3. **Judgment Mechanism:** An "LLM-as-a-Judge" is employed to evaluate the quality of reasoning steps, specifically identifying the `best` step at level `l-1`.
4. **Preference Data Structure:** The generated preference data `{x, s_{1~l-1}, s_l^b, s_l^w}` explicitly pairs a "best" (`s_l^b`) and "worst" (`s_l^w`) step for the same prefix reasoning chain (`s_{1~l-1}`), given the original input `x`.
5. **Iterative Refinement:** The process is cyclical. The model `Mᵢ` generates steps, is judged, creates preference data, is optimized into `M_{i+1}`, and then `M_{i+1}` becomes the new `Mᵢ` for the next iteration.
### Interpretation
This diagram outlines a sophisticated reinforcement learning from human feedback (RLHF) or AI feedback (RLAIF) pipeline tailored for improving the *reasoning process* of a language model, not just its final answers.
* **What it demonstrates:** The pipeline aims to teach a model not just *what* to answer, but *how* to think step-by-step. By generating multiple reasoning paths, judging the quality of individual steps, and then optimizing the model to prefer better steps over worse ones, it seeks to instill more reliable, logical, and accurate reasoning chains.
* **Relationships:** The EFT Data provides the raw material for exploration (multiple step options). The LLM-as-a-Judge provides the evaluation signal. The Step-wise Preference Optimization is the learning algorithm that translates these judgments into model updates. The loop ensures continuous improvement.
* **Notable Implications:** This approach could mitigate issues where a model arrives at a correct answer via flawed logic. By penalizing poor intermediate steps (the `s_l^w` in the preference data), the model is encouraged to develop robust reasoning patterns. The use of an LLM judge suggests scalability, as it doesn't rely solely on human annotation for each step. The clear separation between initialization (using standard IFT/EFT data) and the iterative step-wise loop highlights this as a specialized, secondary training phase.
DECODING INTELLIGENCE...