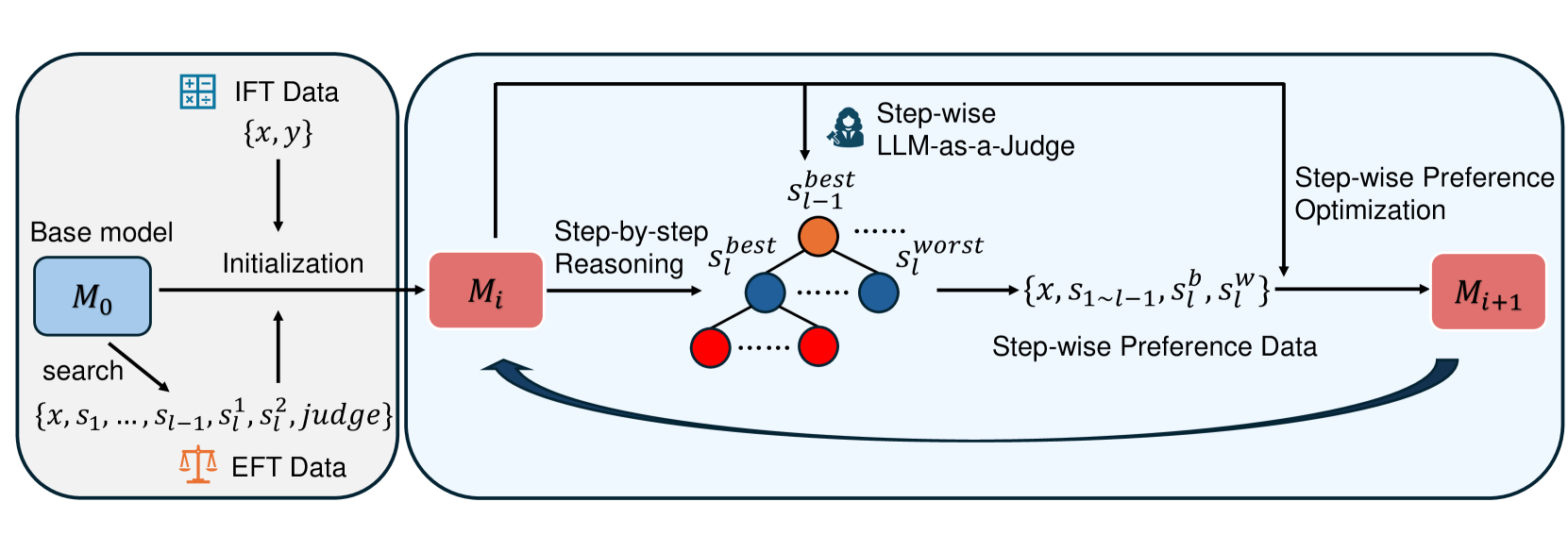
## Flowchart: Machine Learning Model Optimization Pipeline
### Overview
The diagram illustrates a multi-stage machine learning optimization process involving iterative model refinement through step-wise reasoning, preference optimization, and feedback loops. The pipeline integrates initial fine-tuning (IFT) data, evolutionary fine-tuning (EFT) data, and large language model (LLM) evaluations.
### Components/Axes
1. **Left Section (Model Initialization & Search)**
- **Base Model (M₀)**: Blue box containing initial model parameters
- **IFT Data**: {x, y} pairs (input-output training data)
- **EFT Data**: Represented by balance scale icon, containing search parameters {x, s₁, ..., s_{l-1}, s_l¹, s_l², judge}
- **Initialization Arrow**: Connects M₀ to M_i (first iteration model)
- **Search Process**: Explicitly labeled "search" with parameter exploration
2. **Right Section (Step-wise Optimization)**
- **Step-by-Step Reasoning**: Orange-to-blue gradient nodes representing step evaluations
- s_{l-1}^best (orange)
- s_l^best (blue)
- s_l^worst (red)
- **Step-wise LLM-as-a-Judge**: Central evaluation component
- **Step-wise Preference Optimization**: Right-side optimization process
- **Step-wise Preference Data**: {x, s_{1~l-1}, s_l^b, s_l^w} format
- **Model Iteration**: M_i → M_{i+1} progression with feedback loop
3. **Color Legend**
- Blue: Best-performing steps/parameters
- Red: Worst-performing steps/parameters
- Orange: Intermediate/initial steps
- Black: Process flow arrows
### Detailed Analysis
- **Model Evolution Flow**:
M₀ → Initialization → M_i → Step-by-Step Reasoning → Step-wise Preference Optimization → M_{i+1}
with feedback loop from M_{i+1} back to M_i
- **Parameter Evaluation**:
- s_l^best (blue) represents optimal step
- s_l^worst (red) represents suboptimal step
- s_{l-1}^best (orange) shows previous iteration's best step
- **Data Integration**:
- IFT data provides initial training foundation
- EFT data enables parameter exploration through search
- Step-wise preference data captures LLM evaluations for optimization
### Key Observations
1. **Iterative Improvement**: The feedback loop between M_i and M_{i+1} suggests continuous model refinement
2. **LLM Evaluation Role**: The "LLM-as-a-Judge" component acts as quality control for step-wise reasoning
3. **Preference Optimization**: Explicit preference data ({s_l^b, s_l^w}) enables comparative learning
4. **Parameter Exploration**: The search process explores multiple parameter combinations (s₁ to s_l²)
### Interpretation
This pipeline demonstrates a sophisticated approach to model optimization that combines:
1. **Data-Driven Initialization**: Using both IFT and EFT data for foundational training
2. **Step-wise Evaluation**: Breaking down reasoning into discrete steps for granular assessment
3. **LLM-Guided Optimization**: Leveraging large language models for quality judgment
4. **Preference Learning**: Using comparative preferences to refine model behavior
The balance scale icon in EFT data suggests a trade-off optimization approach, while the color-coded step evaluations provide visual representation of performance gradients. The bidirectional flow between model iterations indicates an active learning framework where each cycle improves upon the previous version through explicit preference signals.