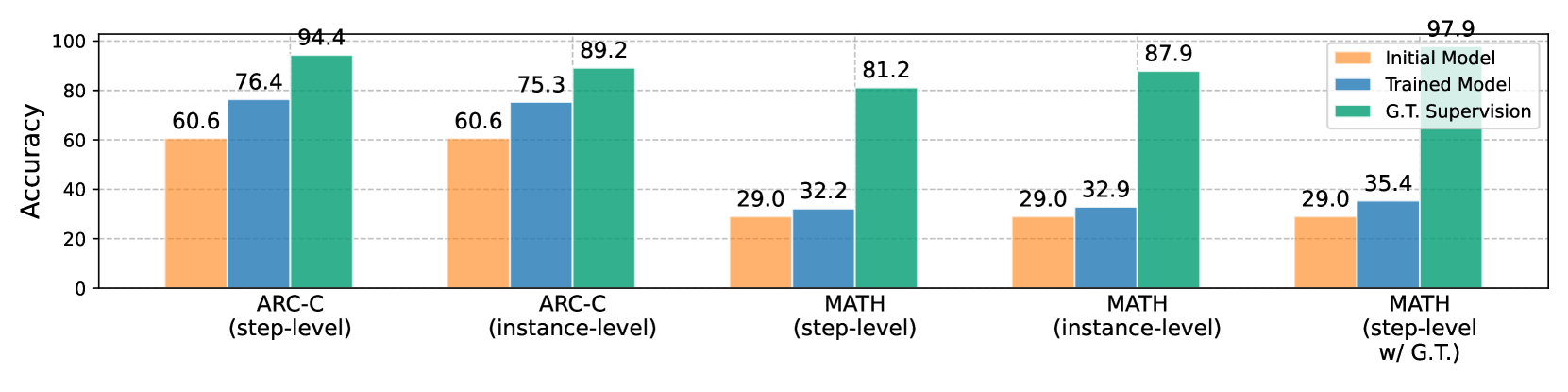
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of three different models (Initial Model, Trained Model, and G.T. Supervision) on two datasets (ARC-C and MATH) under different conditions (step-level, instance-level, and step-level with G.T.). The y-axis represents accuracy, ranging from 0 to 100.
### Components/Axes
* **Y-axis:** Accuracy (ranging from 0 to 100, with gridlines at intervals of 20)
* **X-axis:** Categorical axis representing different datasets and conditions:
* ARC-C (step-level)
* ARC-C (instance-level)
* MATH (step-level)
* MATH (instance-level)
* MATH (step-level w/ G.T.)
* **Legend (top-right):**
* Orange: Initial Model
* Blue: Trained Model
* Green: G.T. Supervision
### Detailed Analysis
The chart presents accuracy values for each model across different datasets and conditions.
* **ARC-C (step-level):**
* Initial Model (Orange): 60.6
* Trained Model (Blue): 76.4
* G.T. Supervision (Green): 94.4
* **ARC-C (instance-level):**
* Initial Model (Orange): 60.6
* Trained Model (Blue): 75.3
* G.T. Supervision (Green): 89.2
* **MATH (step-level):**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 32.2
* G.T. Supervision (Green): 81.2
* **MATH (instance-level):**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 32.9
* G.T. Supervision (Green): 87.9
* **MATH (step-level w/ G.T.):**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 35.4
* G.T. Supervision (Green): 97.9
### Key Observations
* The G.T. Supervision model consistently outperforms the Initial and Trained Models across all datasets and conditions.
* The Trained Model shows improvement over the Initial Model in all cases.
* The MATH dataset generally has lower accuracy for the Initial and Trained Models compared to the ARC-C dataset.
* The highest accuracy is achieved by the G.T. Supervision model on the MATH dataset with step-level supervision (97.9).
### Interpretation
The data suggests that training improves model accuracy, but providing ground truth supervision (G.T. Supervision) leads to significantly higher performance. The difference in accuracy between the ARC-C and MATH datasets for the Initial and Trained Models indicates that the MATH dataset may be more challenging. The G.T. Supervision model's high accuracy on the MATH dataset, especially with step-level supervision, suggests that providing detailed guidance during training can effectively address the challenges posed by this dataset. The "step-level w/ G.T." condition for the MATH dataset yields the best performance, indicating that providing ground truth at each step of the problem-solving process is highly beneficial.