## Bar Chart: Model Saliency Comparison
### Overview
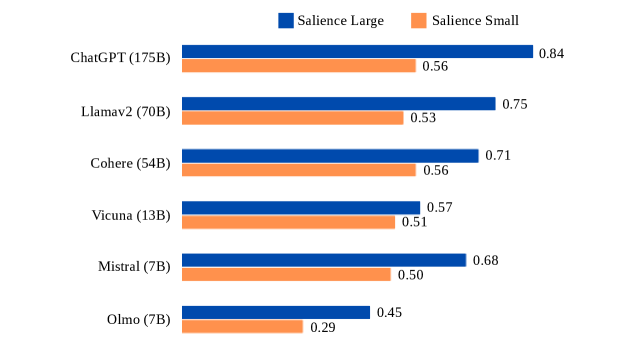
The image is a horizontal bar chart comparing the "Salience Large" and "Salience Small" values for different language models: ChatGPT (175B), Llama v2 (70B), Cohere (54B), Vicuna (13B), Mistral (7B), and Olmo (7B). The chart displays two bars for each model, one representing "Salience Large" (blue) and the other representing "Salience Small" (orange). The numerical values for each bar are displayed at the end of the bar.
### Components/Axes
* **Y-axis:** Categorical axis listing the language models: ChatGPT (175B), Llama v2 (70B), Cohere (54B), Vicuna (13B), Mistral (7B), and Olmo (7B).
* **X-axis:** Numerical axis representing the salience values. The scale is implied to range from 0 to approximately 0.9, based on the data values.
* **Legend:** Located at the top of the chart, indicating "Salience Large" (blue) and "Salience Small" (orange).
### Detailed Analysis
Here's a breakdown of the salience values for each model:
* **ChatGPT (175B):**
* Salience Large: 0.84
* Salience Small: 0.56
* **Llama v2 (70B):**
* Salience Large: 0.75
* Salience Small: 0.53
* **Cohere (54B):**
* Salience Large: 0.71
* Salience Small: 0.56
* **Vicuna (13B):**
* Salience Large: 0.57
* Salience Small: 0.51
* **Mistral (7B):**
* Salience Large: 0.68
* Salience Small: 0.50
* **Olmo (7B):**
* Salience Large: 0.45
* Salience Small: 0.29
### Key Observations
* For all models, "Salience Large" is greater than "Salience Small."
* ChatGPT (175B) has the highest "Salience Large" value (0.84).
* Olmo (7B) has the lowest "Salience Large" value (0.45) and the lowest "Salience Small" value (0.29).
* The difference between "Salience Large" and "Salience Small" is most significant for Olmo (7B) and ChatGPT (175B).
### Interpretation
The chart compares the salience of different language models under two conditions: "Large" and "Small." The specific meaning of "Salience Large" and "Salience Small" is not defined in the image, but it can be inferred that they represent different configurations or settings affecting the model's salience. The data suggests that larger models (e.g., ChatGPT) tend to have higher salience values overall. The difference between "Salience Large" and "Salience Small" varies across models, indicating that some models are more sensitive to the "size" parameter than others. Olmo (7B) shows the lowest salience values in both conditions, suggesting it may be less effective or optimized compared to the other models. The chart highlights the relative performance of these models in terms of salience, providing a basis for comparison and further investigation into the factors influencing salience in language models.