## Horizontal Bar Chart: Salience Scores by AI Model and Parameter Size
### Overview
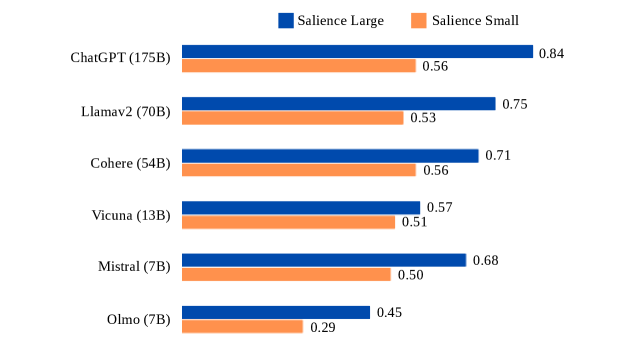
This image is a horizontal bar chart comparing the "Salience Large" and "Salience Small" scores for six different large language models (LLMs). The chart visually contrasts the performance of each model across these two metrics, with models listed vertically and their corresponding scores represented by horizontal bars.
### Components/Axes
* **Chart Type:** Horizontal grouped bar chart.
* **Y-Axis (Vertical):** Lists six AI models, each followed by its approximate parameter count in parentheses. From top to bottom:
1. ChatGPT (175B)
2. Llamav2 (70B)
3. Cohere (54B)
4. Vicuna (13B)
5. Mistral (7B)
6. Olmo (7B)
* **X-Axis (Horizontal):** Represents the numerical salience score. The axis is not explicitly labeled with a title or scale markers, but the score values are printed directly at the end of each bar.
* **Legend:** Positioned at the top center of the chart.
* A blue square is labeled **"Salience Large"**.
* An orange square is labeled **"Salience Small"**.
* **Data Series:** Two bars are plotted for each model:
* **Blue Bar:** Represents the "Salience Large" score.
* **Orange Bar:** Represents the "Salience Small" score.
### Detailed Analysis
The chart presents the following specific data points for each model (Salience Large / Salience Small):
1. **ChatGPT (175B):**
* Salience Large (Blue): 0.84
* Salience Small (Orange): 0.56
* *Trend:* The blue bar is significantly longer than the orange bar.
2. **Llamav2 (70B):**
* Salience Large (Blue): 0.75
* Salience Small (Orange): 0.53
* *Trend:* The blue bar is longer than the orange bar.
3. **Cohere (54B):**
* Salience Large (Blue): 0.71
* Salience Small (Orange): 0.56
* *Trend:* The blue bar is longer than the orange bar. Notably, its "Salience Small" score (0.56) is equal to ChatGPT's.
4. **Vicuna (13B):**
* Salience Large (Blue): 0.57
* Salience Small (Orange): 0.51
* *Trend:* The blue bar is slightly longer than the orange bar.
5. **Mistral (7B):**
* Salience Large (Blue): 0.68
* Salience Small (Orange): 0.50
* *Trend:* The blue bar is longer than the orange bar. Its "Salience Large" score is higher than the larger Vicuna model.
6. **Olmo (7B):**
* Salience Large (Blue): 0.45
* Salience Small (Orange): 0.29
* *Trend:* The blue bar is longer than the orange bar. This model has the lowest scores in both categories.
### Key Observations
* **Consistent Pattern:** For every model listed, the "Salience Large" score (blue bar) is higher than the "Salience Small" score (orange bar).
* **Top Performer:** ChatGPT (175B) achieves the highest score in both categories (0.84 Large, 0.56 Small).
* **Lowest Performer:** Olmo (7B) has the lowest scores in both categories (0.45 Large, 0.29 Small).
* **Parameter Size vs. Performance:** While the largest model (ChatGPT) performs best, the relationship is not perfectly linear. For example, Mistral (7B) outperforms the larger Vicuna (13B) on the "Salience Large" metric (0.68 vs. 0.57).
* **Score Equality:** Cohere (54B) and ChatGPT (175B) share the same "Salience Small" score of 0.56.
### Interpretation
This chart likely evaluates how well different LLMs identify or generate salient (important, relevant) information, with "Large" and "Small" possibly referring to the scale or granularity of the salience task (e.g., document-level vs. sentence-level importance).
The data suggests a general correlation between larger model size (parameter count) and higher salience scores, but with notable exceptions. The consistent gap between "Large" and "Small" scores for each model indicates that the task measured by "Salience Large" yields systematically higher scores across all models, or that models are better at the "Large" variant of the task.
The performance of Mistral (7B) is particularly interesting, as it surpasses the larger Vicuna (13B) on the "Salience Large" metric, suggesting that factors beyond raw parameter count—such as training data, architecture, or fine-tuning—significantly impact this specific capability. The chart serves as a comparative benchmark, highlighting that model size alone is not the sole determinant of performance on salience-related tasks.