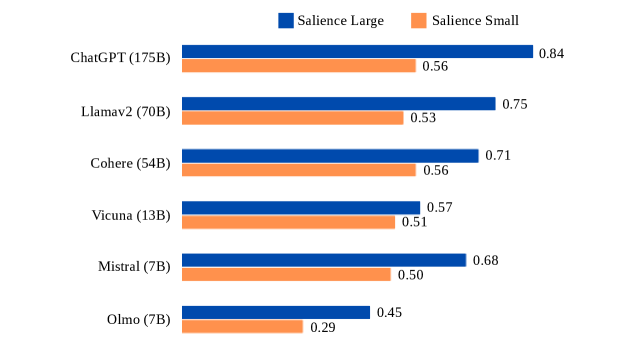
## Bar Chart: Model Performance Comparison (Salience Large vs. Salience Small)
### Overview
The image is a horizontal bar chart comparing performance metrics (Salience Large and Salience Small) across six AI models: ChatGPT (175B), Llamav2 (70B), Cohere (54B), Vicuna (13B), Mistral (7B), and Olmo (7B). The chart uses two colors to distinguish the two metrics: blue for Salience Large and orange for Salience Small. Values are normalized between 0 and 1.
### Components/Axes
- **Y-Axis**: Model names with parameter sizes (e.g., "ChatGPT (175B)") listed from top to bottom.
- **X-Axis**: Performance values (0–1), with no explicit label but implied to represent "Salience Score."
- **Legend**: Located at the top-right corner, with:
- Blue square labeled "Salience Large"
- Orange square labeled "Salience Small"
- **Bars**: Horizontal bars for each model, with Salience Large (blue) on the right and Salience Small (orange) on the left.
### Detailed Analysis
1. **ChatGPT (175B)**:
- Salience Large: 0.84 (blue)
- Salience Small: 0.56 (orange)
2. **Llamav2 (70B)**:
- Salience Large: 0.75 (blue)
- Salience Small: 0.53 (orange)
3. **Cohere (54B)**:
- Salience Large: 0.71 (blue)
- Salience Small: 0.56 (orange)
4. **Vicuna (13B)**:
- Salience Large: 0.57 (blue)
- Salience Small: 0.51 (orange)
5. **Mistral (7B)**:
- Salience Large: 0.68 (blue)
- Salience Small: 0.50 (orange)
6. **Olmo (7B)**:
- Salience Large: 0.45 (blue)
- Salience Small: 0.29 (orange)
### Key Observations
- **Salience Large vs. Small**: For all models, Salience Large scores are consistently higher than Salience Small scores (e.g., ChatGPT: 0.84 vs. 0.56).
- **Model Size Correlation**: Larger models (e.g., ChatGPT 175B) generally have higher Salience Large scores, but exceptions exist (e.g., Cohere 54B outperforms Llamav2 70B in Salience Large).
- **Lowest Performance**: Olmo (7B) has the lowest scores for both metrics (0.45 and 0.29).
- **Smallest Gap**: Vicuna (13B) has the narrowest difference between Salience Large (0.57) and Salience Small (0.51).
### Interpretation
The chart suggests that larger models (e.g., ChatGPT, Llamav2) tend to perform better on the Salience Large metric, which may reflect their capacity to handle complex tasks. However, the smaller models (e.g., Mistral, Olmo) show significant gaps between the two metrics, indicating potential limitations in scalability or efficiency. The exception of Cohere (54B) outperforming Llamav2 (70B) in Salience Large highlights that model architecture or training data may play a critical role beyond size alone. Olmo’s low scores suggest it may struggle with the evaluated criteria compared to its peers.