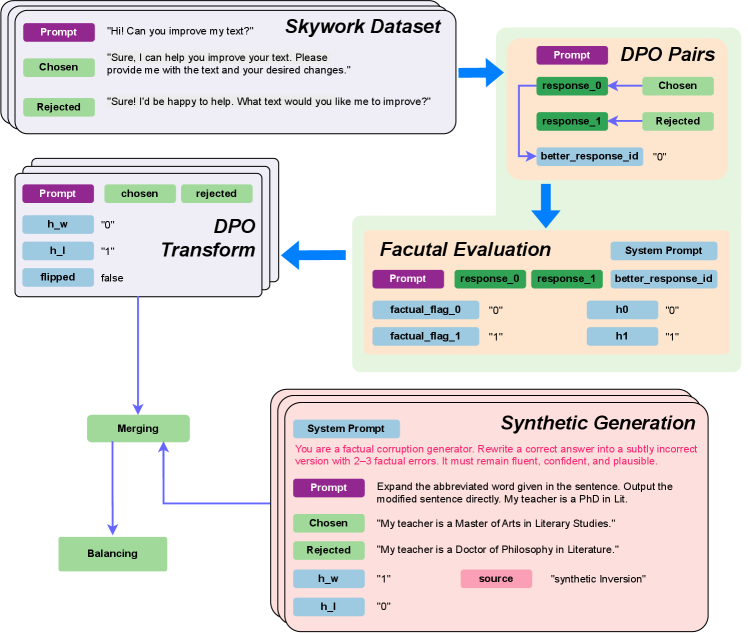
## Diagram: Skywork Dataset Generation and Processing
### Overview
The image presents a diagram illustrating the process of generating and processing the Skywork Dataset. It outlines the steps from initial prompt creation to synthetic generation, incorporating DPO (Direct Preference Optimization) and factual evaluation. The diagram shows the flow of data and transformations applied at each stage.
### Components/Axes
The diagram consists of several key components:
1. **Skywork Dataset:** The initial stage, involving prompts and responses.
2. **DPO Pairs:** Represents the pairing of chosen and rejected responses.
3. **DPO Transform:** Transforms the data using DPO principles.
4. **Merging:** Combines data from different sources.
5. **Balancing:** Balances the dataset.
6. **Factual Evaluation:** Evaluates the factual accuracy of responses.
7. **Synthetic Generation:** Generates synthetic data with controlled factual errors.
The diagram uses color-coding to distinguish different types of data:
* **Purple:** Prompts
* **Light Green:** Chosen/Rejected responses, and intermediate processing steps.
* **Light Blue:** System prompts and flags.
* **Pink:** Source and synthetic inversion.
### Detailed Analysis
**1. Skywork Dataset (Top-Left)**
* **Prompt:** "Hi! Can you improve my text?"
* **Chosen:** "Sure, I can help you improve your text. Please provide me with the text and your desired changes."
* **Rejected:** "Sure! I'd be happy to help. What text would you like me to improve?"
**2. DPO Pairs (Top-Right)**
* **Prompt:** (Implied, connected from Skywork Dataset)
* **response_0:** Connected to "Chosen"
* **response_1:** Connected to "Rejected"
* **Chosen:** (Light Green)
* **Rejected:** (Light Green)
* **better_response_id:** "0" (Light Blue)
**3. DPO Transform (Center-Left)**
* **Prompt:** (Purple)
* **chosen:** (Light Green)
* **rejected:** (Light Green)
* **h_w:** "0" (Light Blue)
* **h_l:** "1" (Light Blue)
* **flipped:** false (Light Blue)
**4. Merging and Balancing (Bottom-Left)**
* **Merging:** (Light Green) - Receives input from DPO Transform.
* **Balancing:** (Light Green) - Receives input from Merging and feeds back into Merging.
**5. Factual Evaluation (Center)**
* **System Prompt:** (Light Blue)
* **Prompt:** (Purple)
* **response_0:** (Light Green)
* **response_1:** (Light Green)
* **better_response_id:** (Light Blue)
* **factual_flag_0:** "0" (Light Blue)
* **factual_flag_1:** "1" (Light Blue)
* **h0:** "0" (Light Blue)
* **h1:** "1" (Light Blue)
**6. Synthetic Generation (Bottom-Right)**
* **System Prompt:** "You are a factual corruption generator. Rewrite a correct answer into a subtly incorrect version with 2-3 factual errors. It must remain fluent, confident, and plausible." (Light Blue)
* **Prompt:** "Expand the abbreviated word given in the sentence. Output the modified sentence directly. My teacher is a PhD in Lit." (Purple)
* **Chosen:** "My teacher is a Master of Arts in Literary Studies." (Light Green)
* **Rejected:** "My teacher is a Doctor of Philosophy in Literature." (Light Green)
* **h_w:** "1" (Light Blue)
* **h_l:** "0" (Light Blue)
* **source:** (Pink)
* **synthetic Inversion:** (Pink)
### Key Observations
* The diagram illustrates a pipeline for generating and refining a dataset.
* DPO is used to rank responses, and factual evaluation is used to assess accuracy.
* Synthetic generation introduces controlled errors to create a more diverse dataset.
* The flow is generally top-down, with feedback loops in the merging/balancing stage.
### Interpretation
The diagram describes a sophisticated process for creating a dataset suitable for training language models. The use of DPO allows for preference-based ranking of responses, while factual evaluation ensures the accuracy of the data. The synthetic generation step is particularly interesting, as it allows for the creation of a dataset with controlled errors, which can be used to train models to be more robust to factual inaccuracies. The feedback loop between merging and balancing suggests an iterative process to refine the dataset's composition. The entire process aims to create a high-quality dataset for training language models, specifically focusing on improving text and ensuring factual correctness.