TECHNICAL ASSET FINGERPRINT
acec28aa14cbfaeb82f10b76
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
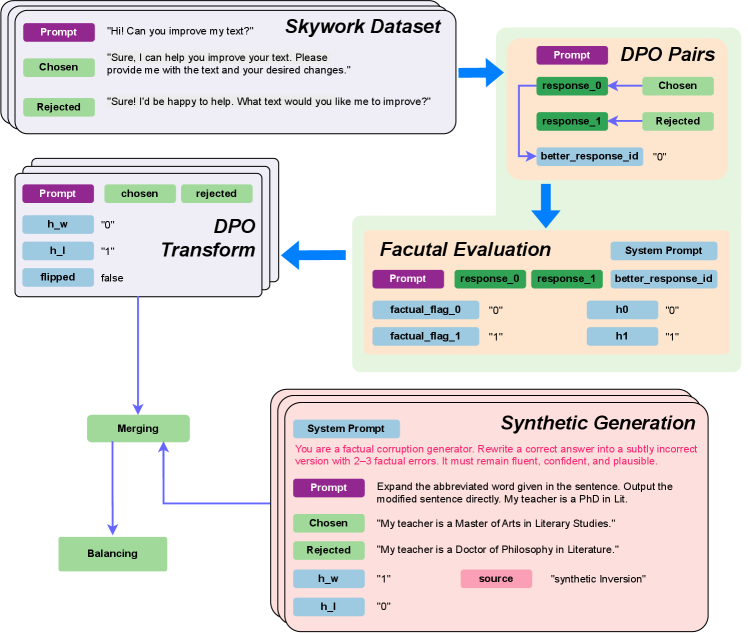
## Diagram: DPO (Direct Preference Optimization) Data Processing Pipeline
### Overview
This image is a technical flowchart illustrating a multi-stage data processing pipeline for creating and evaluating Direct Preference Optimization (DPO) pairs. The pipeline integrates a base dataset ("Skywork Dataset"), transforms it, performs factual evaluation, and incorporates synthetically generated data to create a balanced training set. The diagram uses color-coded boxes and directional arrows to show the flow of data and operations.
### Components/Axes
The diagram is organized into several interconnected components, primarily flowing from top to bottom and left to right.
**1. Skywork Dataset (Top-Left)**
* **Structure:** A stack of three cards, indicating a dataset.
* **Content (Transcribed):**
* **Prompt (Purple Header):** "Hi! Can you improve my text?"
* **Chosen (Green Header):** "Sure, I can help you improve your text. Please provide me with the text and your desired changes."
* **Rejected (Red Header):** "Sure! I'd be happy to help. What text would you like me to improve?"
* **Function:** Serves as the initial source of human preference data (chosen vs. rejected responses to a prompt).
**2. DPO Pairs (Top-Right)**
* **Structure:** A light green box containing labeled data fields.
* **Content (Transcribed):**
* **Prompt (Purple Header)**
* **response_0 (Green Header):** Linked to "Chosen" from the Skywork Dataset.
* **response_1 (Red Header):** Linked to "Rejected" from the Skywork Dataset.
* **better_response_id (Blue Header):** Value is `"0"`, indicating `response_0` (the chosen response) is preferred.
* **Function:** Represents the structured format of a DPO training example, pairing a prompt with a preferred and a dispreferred response.
**3. Factual Evaluation (Center-Right)**
* **Structure:** A light green box containing evaluation metadata.
* **Content (Transcribed):**
* **System Prompt (Blue Header):** (Text not fully visible, but label is present).
* **Prompt (Purple Header)**
* **response_0 (Green Header)**
* **response_1 (Red Header)**
* **better_response_id (Blue Header)**
* **factual_flag_0 (Blue Header):** Value is `"0"`.
* **factual_flag_1 (Blue Header):** Value is `"1"`.
* **h0 (Blue Header):** Value is `"0"`.
* **h1 (Blue Header):** Value is `"1"`.
* **Function:** Adds factual accuracy assessment to the DPO pair. The flags (`factual_flag_0=0`, `factual_flag_1=1`) suggest `response_0` is factually correct and `response_1` is factually incorrect in this example.
**4. DPO Transform (Center-Left)**
* **Structure:** A stack of three cards, mirroring the input dataset structure but with added transformation metadata.
* **Content (Transcribed):**
* **Prompt (Purple Header)**
* **chosen (Green Header)**
* **rejected (Red Header)**
* **h_w (Blue Header):** Value is `"0"`.
* **h_l (Blue Header):** Value is `"1"`.
* **flipped (Blue Header):** Value is `false`.
* **Function:** Represents the DPO pair after potential transformations. `h_w` and `h_l` likely correspond to the factual flags for the winning (chosen) and losing (rejected) responses. `flipped: false` indicates the preference order was not reversed.
**5. Synthetic Generation (Bottom-Right)**
* **Structure:** A pinkish box containing a generation task example.
* **Content (Transcribed):**
* **System Prompt (Blue Header):** "You are a factual corruption generator. Rewrite a correct answer into a subtly incorrect version with 2-3 factual errors. It must remain fluent, confident, and plausible."
* **Prompt (Purple Header):** "Expand the abbreviated word given in the sentence. Output the modified sentence directly. My teacher is a PhD in Lit."
* **Chosen (Green Header):** "My teacher is a Master of Arts in Literary Studies."
* **Rejected (Red Header):** "My teacher is a Doctor of Philosophy in Literature."
* **h_w (Blue Header):** Value is `"1"`.
* **h_l (Blue Header):** Value is `"0"`.
* **source (Pink Header):** Value is `"synthetic inversion"`.
* **Function:** Demonstrates the creation of a synthetic DPO pair where the "chosen" response is factually incorrect (corrupted) and the "rejected" response is correct. This inverts the typical preference, as shown by `h_w=1` (incorrect) and `h_l=0` (correct). The `source` tag identifies its origin.
**6. Merging & Balancing (Bottom-Left)**
* **Structure:** Two green boxes connected by a downward arrow.
* **Labels:** "Merging" and "Balancing".
* **Function:** Represents the final stages where the transformed real data and the synthetic data are combined ("Merging") and then likely adjusted for class balance ("Balancing") to create the final training dataset.
**Flow Arrows:**
* Skywork Dataset → DPO Pairs
* DPO Pairs → Factual Evaluation
* Factual Evaluation → DPO Transform
* Synthetic Generation → Merging
* DPO Transform → Merging
* Merging → Balancing
### Detailed Analysis
The pipeline processes data through distinct stages:
1. **Initial Pairing:** A human-preference dataset (Skywork) is formatted into DPO pairs (Prompt, response_0, response_1, better_response_id).
2. **Factual Augmentation:** Each pair is evaluated for factual correctness, adding flags (`factual_flag_0`, `factual_flag_1`) and corresponding hidden state indicators (`h0`, `h1`).
3. **Transformation:** The pair is transformed into a training-ready format (`DPO Transform`), carrying over the factual correctness signals as `h_w` (for the winning/chosen response) and `h_l` (for the losing/rejected response). In the example, the chosen response is correct (`h_w=0`).
4. **Synthetic Data Injection:** A separate process generates synthetic DPO pairs designed to teach the model to identify factual errors. In the example, the "chosen" response is a fluent but incorrect corruption of the prompt, while the "rejected" response is the correct expansion. This creates a training signal where the model should learn to prefer the factually correct answer (`h_l=0`) over the plausible but wrong one (`h_w=1`).
5. **Final Assembly:** Real and synthetic data streams are merged and balanced.
### Key Observations
* **Color Coding Consistency:** Purple = Prompt, Green = Chosen/Preferred Response, Red = Rejected Response, Blue = Metadata/Flags. This is consistent across all components.
* **Factual Signal Inversion:** The core innovation shown is the use of synthetic data to create *inverted* preference pairs (`source: "synthetic inversion"`). Here, the factually incorrect response is labeled as "chosen" to explicitly train the model to discern and avoid such errors.
* **Metadata Propagation:** Factual correctness information (`0` for correct, `1` for incorrect) flows from the evaluation stage (`factual_flag_0/1`) into the transform stage as `h_w/h_l`.
* **Pipeline Integration:** The diagram clearly shows that the final training data is a hybrid of human-preference data and synthetically generated factual-corruption data.
### Interpretation
This diagram outlines a sophisticated methodology for improving the factual reliability of language models using DPO. The pipeline does not rely solely on human preference data, which may not explicitly penalize factual errors. Instead, it actively engineers training examples where the model must learn to reject plausible but factually incorrect responses.
The **"Synthetic Generation"** component is particularly significant. By using a "factual corruption generator," the system creates challenging negative examples. The model is trained not just on "good vs. bad" responses, but on "correct vs. subtly incorrect" responses, forcing it to develop a more nuanced understanding of factual accuracy. The **"Merging"** and **"Balancing"** steps ensure the final dataset contains a healthy mix of standard preference data and these specialized factual-correction examples, leading to a model that is both helpful and truthful. The entire process is a form of targeted, synthetic data augmentation for alignment.
DECODING INTELLIGENCE...