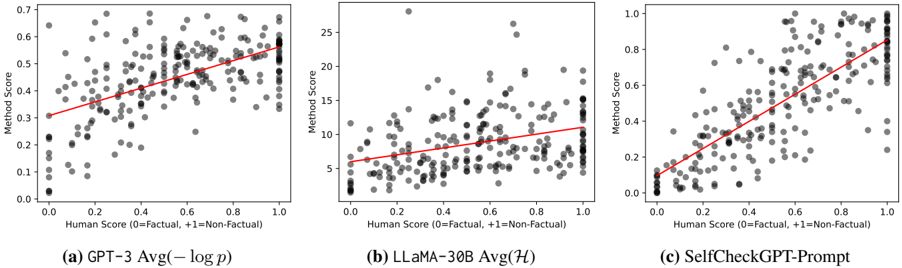
## Scatter Plots: Method Score vs. Human Score for Factualness
### Overview
The image presents three scatter plots comparing the "Method Score" against the "Human Score" for factualness, where 0 represents factual and +1 represents non-factual. Each plot represents a different method: GPT-3 Avg(-log p), LLaMA-30B Avg(H), and SelfCheckGPT-Prompt. A red line is overlaid on each scatter plot, indicating a trend line.
### Components/Axes
* **X-axis (Horizontal):** "Human Score (0=Factual, +1=Non-Factual)". The scale ranges from 0.0 to 1.0 in increments of 0.2.
* **Y-axis (Vertical):** "Method Score". The scale varies for each plot:
* **(a) GPT-3 Avg(-log p):** 0.0 to 0.7 in increments of 0.1.
* **(b) LLaMA-30B Avg(H):** 0 to 25 in increments of 5.
* **(c) SelfCheckGPT-Prompt:** 0.0 to 1.0 in increments of 0.2.
* **Data Points:** Grey circles represent individual data points.
* **Trend Line:** A red line is overlaid on each scatter plot.
### Detailed Analysis
#### (a) GPT-3 Avg(-log p)
* **X-axis:** Human Score (0 to 1)
* **Y-axis:** Method Score (0 to 0.7)
* **Trend:** The red trend line slopes upward, indicating a positive correlation between the Human Score and the Method Score.
* **Data Points:**
* At Human Score = 0, Method Scores range from approximately 0 to 0.3.
* At Human Score = 1, Method Scores range from approximately 0.3 to 0.6.
#### (b) LLaMA-30B Avg(H)
* **X-axis:** Human Score (0 to 1)
* **Y-axis:** Method Score (0 to 25)
* **Trend:** The red trend line slopes slightly upward, indicating a weak positive correlation between the Human Score and the Method Score.
* **Data Points:**
* At Human Score = 0, Method Scores range from approximately 1 to 6.
* At Human Score = 1, Method Scores range from approximately 3 to 10.
#### (c) SelfCheckGPT-Prompt
* **X-axis:** Human Score (0 to 1)
* **Y-axis:** Method Score (0 to 1)
* **Trend:** The red trend line slopes upward, indicating a strong positive correlation between the Human Score and the Method Score.
* **Data Points:**
* At Human Score = 0, Method Scores range from approximately 0 to 0.2.
* At Human Score = 1, Method Scores range from approximately 0.4 to 1.0.
### Key Observations
* SelfCheckGPT-Prompt shows the strongest positive correlation between Human Score and Method Score.
* LLaMA-30B Avg(H) shows a much weaker correlation and a different scale for the Method Score.
* All three plots show a general trend of increasing Method Score as Human Score increases, suggesting that as the human assessment of non-factualness increases, the method score also tends to increase.
### Interpretation
The plots compare the performance of different methods in assessing the factualness of text generated by language models against human evaluations. The upward trend in all three plots suggests that the methods generally agree with human assessments, with higher method scores corresponding to higher human scores for non-factualness. The varying slopes of the trend lines indicate differences in the strength of this correlation among the methods. SelfCheckGPT-Prompt appears to align most closely with human evaluations, while LLaMA-30B Avg(H) shows a weaker correlation. The different scales on the Y-axis also suggest that the methods use different scoring systems or metrics.