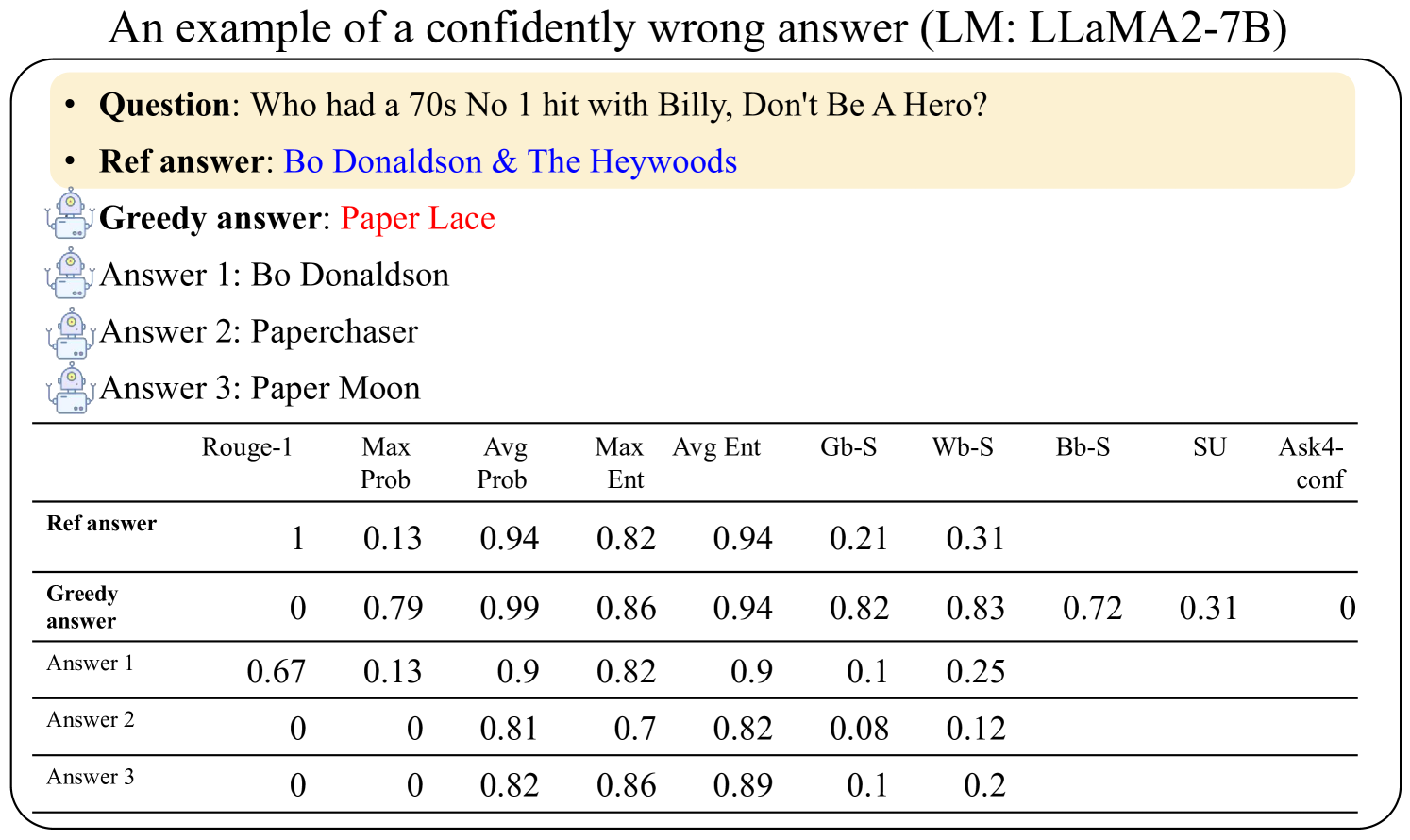
\n
## Data Table: Confidently Wrong Answer Analysis (LLaMA2-7B)
### Overview
This document presents an analysis of the responses generated by the LLaMA2-7B language model to a specific question. It compares the model's "greedy answer" and other potential answers to a reference answer, evaluating their similarity using several metrics. The document highlights a case where the model provides a confident but incorrect answer.
### Components/Axes
The document consists of a textual description of the scenario, followed by a data table. The table has the following structure:
* **Rows:** Represent different answers: "Ref answer" (reference answer), "Greedy answer" (the model's initial response), "Answer 1", "Answer 2", and "Answer 3".
* **Columns:** Represent evaluation metrics: "Rogue-1", "Max Prob", "Avg Prob", "Max Ent", "Avg Ent", "Gb-S", "Wb-S", "Bb-S", "SU", and "Ask4-conf".
The top section of the document provides the question and the answers.
### Content Details
The question posed is: "Who had a 70s No 1 hit with Billy, Don't Be A Hero?"
The reference answer is: "Bo Donaldson & The Heywoods".
The greedy answer provided by the model is: "Paper Lace".
Other answers considered are:
* Answer 1: "Bo Donaldson"
* Answer 2: "Paperchaser"
* Answer 3: "Paper Moon"
The data table contains the following numerical values (approximate, due to image quality):
| Answer | Rogue-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
|---------------|---------|----------|----------|---------|---------|-------|-------|-------|-------|-----------|
| Ref answer | 1 | 0.13 | 0.94 | 0.82 | 0.94 | 0.21 | 0.31 | | | |
| Greedy answer | 0 | 0.79 | 0.99 | 0.86 | 0.94 | 0.82 | 0.83 | 0.72 | 0.31 | 0 |
| Answer 1 | 0.67 | 0.13 | 0.9 | 0.82 | 0.9 | 0.1 | 0.25 | | | |
| Answer 2 | 0 | 0 | 0.81 | 0.7 | 0.82 | 0.08 | 0.12 | | | |
| Answer 3 | 0 | 0 | 0.82 | 0.86 | 0.89 | | 0.2 | | | |
### Key Observations
* The "Greedy answer" has a high "Max Prob" (0.79) and "Avg Prob" (0.99), indicating the model was very confident in its response.
* However, the "Rogue-1" score for the "Greedy answer" is 0, indicating no overlap with the reference answer.
* "Answer 1" ("Bo Donaldson") has a Rogue-1 score of 0.67, suggesting it's the closest answer to the reference, despite having lower probabilities.
* The "Ask4-conf" metric is 0 for all answers except the reference answer, which is not provided.
### Interpretation
This document demonstrates a case of the LLaMA2-7B model exhibiting "hallucination" – generating a confident but factually incorrect answer. The high probability scores associated with the "Greedy answer" suggest the model is internally consistent but disconnected from the ground truth. The "Rogue-1" score serves as a critical indicator of factual accuracy, revealing the discrepancy between the model's confidence and correctness. The other answers show varying degrees of similarity to the correct answer, with "Answer 1" being the most plausible alternative. This example highlights the importance of evaluating language model outputs not only for fluency and coherence but also for factual accuracy, especially in applications where reliability is paramount. The metrics used (Rogue-1, probabilities, entropies) provide a quantitative framework for assessing these aspects.