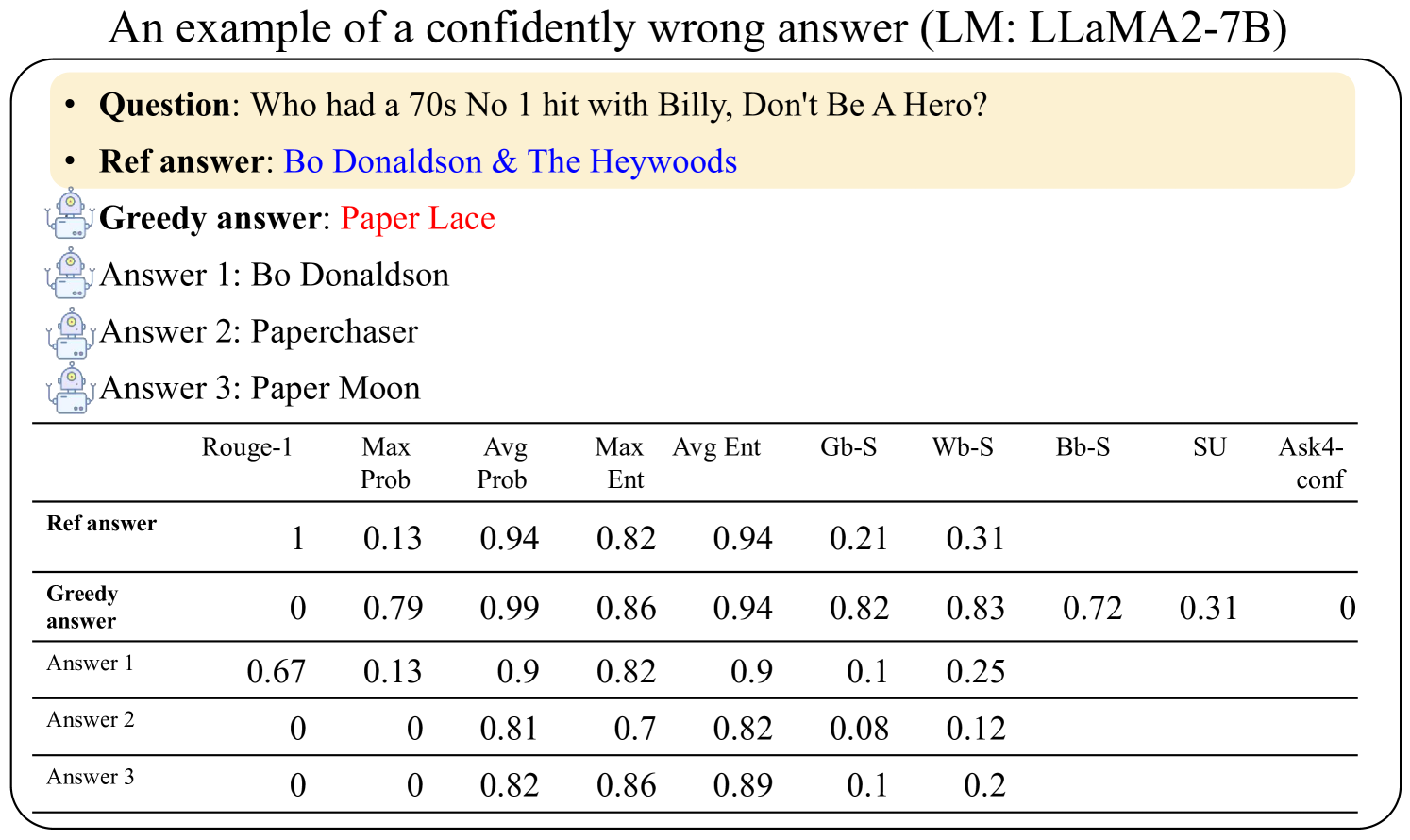
## Data Table with Accompanying Text: Example of a Confidently Wrong Answer from LLaMA2-7B
### Overview
The image is a figure, likely from a research paper or technical report, illustrating an example of a language model (LLaMA2-7B) providing a "confidently wrong" answer to a factual question. It presents the question, a reference answer, several model-generated answers, and a table of associated confidence and similarity metrics for each answer.
### Components/Axes
The image is structured in three main vertical sections:
1. **Title (Top Center):** "An example of a confidently wrong answer (LM: LLaMA2-7B)"
2. **Question & Answer Block (Upper Section):** A beige, rounded rectangle containing:
* **Question:** "Who had a 70s No 1 hit with Billy, Don't Be A Hero?"
* **Ref answer:** "Bo Donaldson & The Heywoods" (displayed in blue text).
3. **Model Answers (Middle Section):** A list of answers generated by the model, each preceded by a small robot icon.
* **Greedy answer:** "Paper Lace" (displayed in red text).
* **Answer 1:** "Bo Donaldson"
* **Answer 2:** "Paperchaser"
* **Answer 3:** "Paper Moon"
4. **Data Table (Lower Section):** A table with 5 rows and 10 columns. The columns are:
* (Row Label Column)
* Rouge-1
* Max Prob
* Avg Prob
* Max Ent
* Avg Ent
* Gb-S
* Wb-S
* Bb-S
* SU
* Ask4-conf
### Detailed Analysis
**Table Data Transcription:**
The table provides quantitative metrics for each answer listed above. The rows correspond to the answers, and the columns to different evaluation metrics.
| Row Label | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
|----------------|---------|----------|----------|---------|---------|------|------|------|------|-----------|
| **Ref answer** | 1 | 0.13 | 0.94 | 0.82 | 0.94 | 0.21 | 0.31 | | | |
| **Greedy answer** | 0 | 0.79 | 0.99 | 0.86 | 0.94 | 0.82 | 0.83 | 0.72 | 0.31 | 0 |
| **Answer 1** | 0.67 | 0.13 | 0.9 | 0.82 | 0.9 | 0.1 | 0.25 | | | |
| **Answer 2** | 0 | 0 | 0.81 | 0.7 | 0.82 | 0.08 | 0.12 | | | |
| **Answer 3** | 0 | 0 | 0.82 | 0.86 | 0.89 | 0.1 | 0.2 | | | |
*Note: Empty cells in the table indicate no data was provided for that metric-answer combination.*
**Key Metric Observations:**
* **Rouge-1:** Measures n-gram overlap with the reference. The reference answer has a perfect score of 1. "Answer 1" ("Bo Donaldson") has a partial overlap (0.67). The "Greedy answer" and others have 0 overlap.
* **Probability (Max/Avg Prob):** The "Greedy answer" has the highest maximum probability (0.79) and average probability (0.99), indicating the model assigned very high confidence to this incorrect token sequence. The reference answer has a much lower max probability (0.13).
* **Entropy (Max/Avg Ent):** Entropy measures uncertainty. Values are relatively high across all answers (0.7 to 0.94), suggesting the model's internal state had significant uncertainty at the token level, even for the high-probability greedy answer.
* **Similarity Scores (Gb-S, Wb-S, Bb-S, SU):** These are likely various semantic similarity metrics. The "Greedy answer" scores highest on Gb-S (0.82) and Wb-S (0.83), suggesting it is semantically similar to the reference in some embedding space, despite being factually wrong. "Answer 1" scores much lower on these metrics.
* **Ask4-conf:** Only the "Greedy answer" has a value here (0), which may represent a specific confidence calibration metric.
### Key Observations
1. **Confident Error:** The "Greedy answer" ("Paper Lace") is factually incorrect but is generated with the highest model confidence (Max Prob 0.79, Avg Prob 0.99).
2. **Partial Correctness:** "Answer 1" ("Bo Donaldson") is partially correct (part of the reference answer) and has a moderate Rouge-1 score (0.67) but very low model confidence (Max Prob 0.13).
3. **Semantic Proximity of Wrong Answer:** The incorrect "Greedy answer" has high semantic similarity scores (Gb-S, Wb-S), indicating the model may have retrieved or generated a conceptually related but factually distinct entity ("Paper Lace" was another 70s band with a hit about a soldier).
4. **Metric Discrepancy:** There is a stark disconnect between the model's internal confidence metrics (high for the wrong answer) and factual accuracy (Rouge-1 of 0).
### Interpretation
This figure demonstrates a critical failure mode in language models: **confident hallucination**. The model (LLaMA2-7B) selects "Paper Lace" as its top (greedy) answer with extremely high probability, despite it being wrong. The data suggests the model's decoding process prioritizes a semantically plausible and high-probability token sequence over factual correctness.
The high semantic similarity scores for the wrong answer imply the model's internal representations place "Paper Lace" close to the correct answer "Bo Donaldson & The Heywoods" in vector space, likely due to shared context (1970s, music, Billboard hits). However, this proximity does not translate to factual accuracy. The low confidence for the partially correct "Answer 1" further shows the model fails to properly weight the correct factual components.
This example underscores the limitation of relying solely on raw model probability or even semantic similarity for factual reliability. It highlights the need for techniques like retrieval augmentation, fact-checking modules, or improved training to align model confidence with truthfulness. The figure serves as a diagnostic tool, showing that a model can be simultaneously "right" in its semantic neighborhood and "wrong" in its specific factual output.