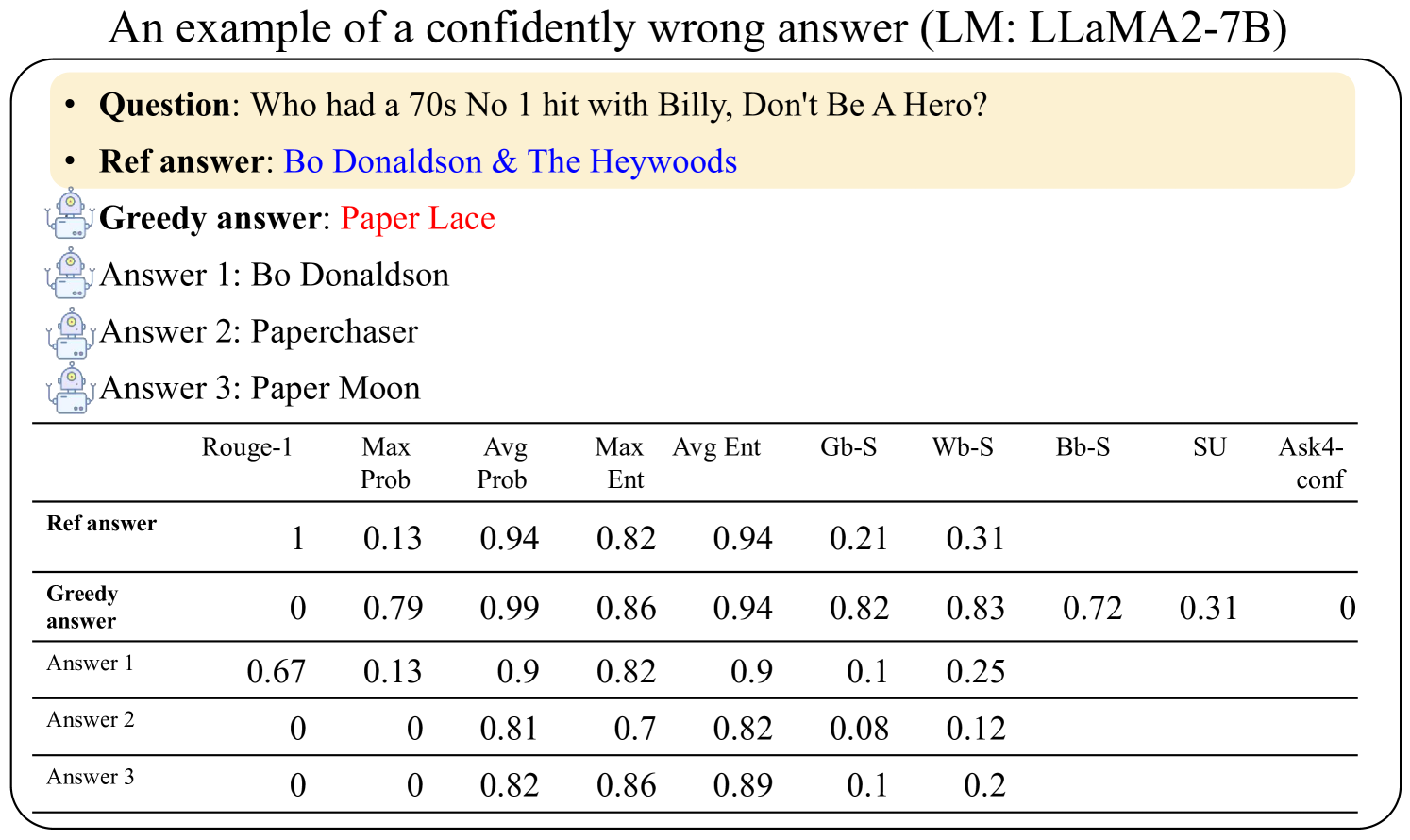
## Table: Model Answer Evaluation Metrics for Trivia Question
### Overview
This table evaluates the performance of different answers to the question "Who had a 70s No.1 hit with Billy, Don't Be A Hero?" using multiple NLP metrics. The reference answer is "Bo Donaldson & The Heywoods," while the model's greedy answer ("Paper Lace") is incorrect. Three candidate answers are scored across 10 metrics.
### Components/Axes
- **Rows**:
1. Reference answer ("Bo Donaldson & The Heywoods")
2. Greedy answer ("Paper Lace")
3. Answer 1 ("Bo Donaldson")
4. Answer 2 ("Paperchaser")
5. Answer 3 ("Paper Moon")
- **Columns**:
- Rouge-1 (rouge score)
- Max Prob (maximum probability)
- Avg Prob (average probability)
- Max Ent (maximum entropy)
- Avg Ent (average entropy)
- Gb-S (grammaticality score)
- Wb-S (word boundary score)
- Bb-S (boundary bigram score)
- SU (semantic unit score)
- Ask4-conf (confidence in Ask4 metric)
### Detailed Analysis
| Metric | Reference Answer | Greedy Answer | Answer 1 | Answer 2 | Answer 3 |
|-----------------|------------------|---------------|----------------|----------------|----------------|
| **Rouge-1** | 1.00 | 0.00 | 0.67 | 0.00 | 0.00 |
| **Max Prob** | 0.13 | 0.79 | 0.13 | 0.00 | 0.00 |
| **Avg Prob** | 0.94 | 0.99 | 0.90 | 0.81 | 0.82 |
| **Max Ent** | 0.82 | 0.86 | 0.82 | 0.70 | 0.86 |
| **Avg Ent** | 0.94 | 0.94 | 0.90 | 0.82 | 0.89 |
| **Gb-S** | 0.21 | 0.82 | 0.10 | 0.08 | 0.10 |
| **Wb-S** | 0.31 | 0.83 | 0.25 | 0.12 | 0.20 |
| **Bb-S** | - | 0.72 | - | - | - |
| **SU** | - | 0.31 | - | - | - |
| **Ask4-conf** | - | 0.00 | - | - | - |
### Key Observations
1. **Reference Answer Dominance**: Scores perfectly on Rouge-1 (1.00) and shows high grammaticality (Wb-S: 0.31) despite lower probability metrics.
2. **Greedy Answer Failure**:
- 0.00 Rouge-1 and Ask4-conf (confidently wrong)
- High Avg Prob (0.99) but poor semantic alignment (SU: 0.31)
3. **Partial Matches**:
- Answer 1 ("Bo Donaldson") shares 0.67 Rouge-1 with reference
- Answer 3 ("Paper Moon") has highest Avg Prob (0.82) among incorrect answers
4. **Metric Discrepancies**:
- Greedy answer has highest Max Prob (0.79) but lowest semantic scores
- Answer 2 ("Paperchaser") shows worst grammaticality (Gb-S: 0.08)
### Interpretation
The data reveals a critical failure mode in the LLaMA2-7B model: **high-confidence generation of semantically irrelevant answers**. While the greedy answer achieves high probability scores (Avg Prob: 0.99), it fails all semantic and grammaticality metrics, demonstrating a disconnect between statistical likelihood and factual accuracy. The reference answer's perfect Rouge-1 score (1.00) contrasts sharply with its lower probability metrics (Max Prob: 0.13), suggesting the model underestimates correct answers when they deviate from common associations. The partial matches (Answers 1 and 3) indicate the model can generate plausible-sounding but incorrect variants, with Answer 3 ("Paper Moon") being the most statistically favored incorrect option. This pattern highlights the need for confidence calibration and semantic grounding in large language models.