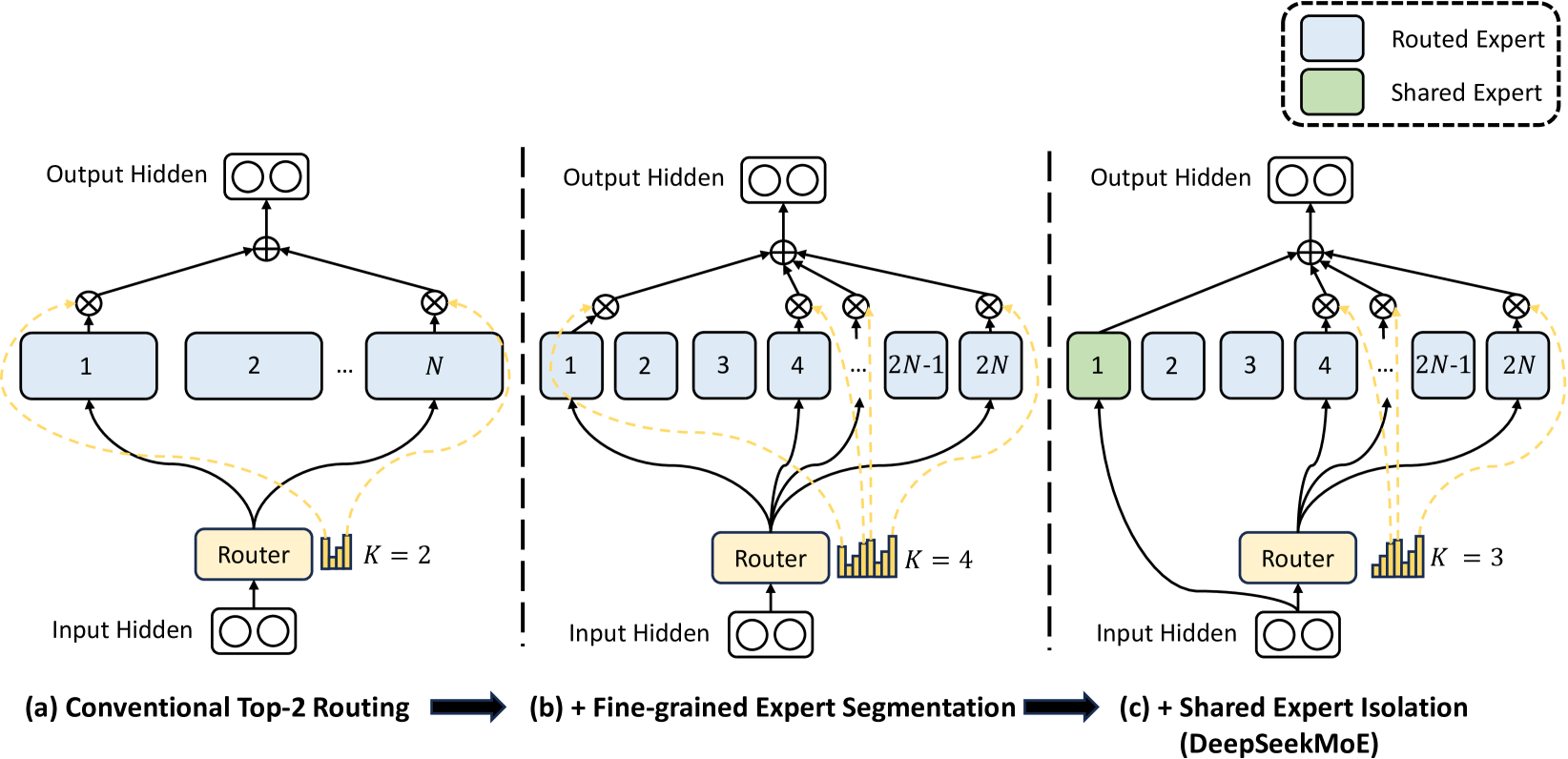
# Technical Diagram Analysis: Expert Routing Strategies in Neural Networks
## Diagram Components and Flow
The image presents three progressive routing architectures for neural networks, each building on the previous with increasing complexity. All diagrams share core components but differ in expert selection strategies.
### Key Elements Across All Diagrams
1. **Input Hidden**: Entry point for data processing (depicted as two circles)
2. **Output Hidden**: Final processing stage (depicted as two circles)
3. **Router**: Central decision-making component (yellow box)
4. **Experts**: Processing units represented by rectangles
- **Routed Experts**: Blue rectangles (specialized for specific tasks)
- **Shared Expert**: Green rectangle (general-purpose processing)
### Diagram Breakdown
#### (a) Conventional Top-2 Routing
- **Expert Configuration**:
- N experts (1 to N)
- Router selects **K=2** experts
- **Flow**:
Input Hidden → Router → Top 2 Experts → Output Hidden
- **Visual Indicators**:
- Dotted yellow arrows show expert routing paths
- Solid black arrows represent data flow
#### (b) + Fine-grained Expert Segmentation
- **Enhancements**:
- Doubled expert count (1 to 2N)
- Router selects **K=4** experts
- **Key Changes**:
- Increased granularity in expert specialization
- More complex routing paths (dotted yellow arrows)
- **Flow**:
Input Hidden → Router → Top 4 Experts → Output Hidden
#### (c) + Shared Expert Isolation (DeepSeekMoE)
- **Architectural Shift**:
- Maintains 2N experts but introduces **K=3** selection
- First expert (green) marked as **Shared Expert**
- **Innovations**:
- Isolation of shared expert functionality
- Hybrid routing strategy combining specialized and general experts
- **Flow**:
Input Hidden → Router → 3 Experts (including Shared Expert) → Output Hidden
## Legend and Color Coding
| Color/Symbol | Component Type | Purpose |
|--------------|----------------------|----------------------------------|
| Blue | Routed Expert | Task-specific processing |
| Green | Shared Expert | General-purpose processing |
| Yellow | Router | Expert selection mechanism |
| Black | Data Flow Arrows | Information propagation |
| Dotted Yellow| Expert Routing Paths | Expert selection visualization |
## Technical Progression
1. **Conventional Routing** (a): Basic top-2 selection from N experts
2. **Fine-grained Segmentation** (b): Increased specialization through doubled expert count
3. **Shared Expert Isolation** (c): Hybrid approach combining specialization with general processing
## Critical Observations
- Router complexity increases with each iteration (K values: 2 → 4 → 3)
- Expert count doubles in (b) then returns to 2N in (c)
- Shared Expert isolation in (c) introduces new architectural paradigm
- All diagrams maintain consistent input/output structure
This progression demonstrates evolving strategies for balancing specialization and generalization in neural network architectures.