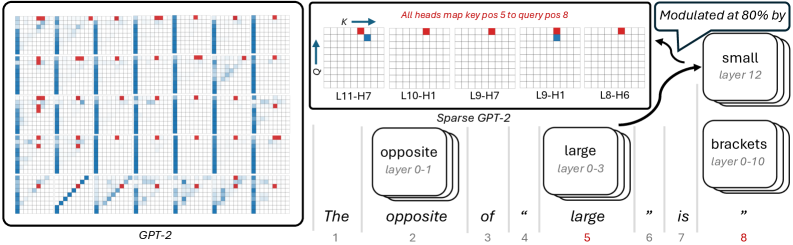
## Diagram: GPT-2 and Sparse GPT-2 Attention Patterns
### Overview
The image presents a comparison of attention patterns in GPT-2 and Sparse GPT-2 models. It visualizes how different heads in various layers attend to specific positions in the input sequence. The left side shows a grid-like representation of attention patterns in GPT-2, while the right side focuses on specific attention heads in Sparse GPT-2, highlighting how they map key position 5 to query position 8. The diagram also indicates which layers modulate the attention at 80% for specific words.
### Components/Axes
* **Left Side:**
* Label: "GPT-2" at the bottom.
* Grid: Represents attention patterns across different layers and heads. Blue indicates attention strength, with darker shades indicating stronger attention. Red squares indicate specific attention points.
* **Top-Right:**
* Label: "All heads map key pos 5 to query pos 8"
* Grids: Five small grids representing attention patterns for specific layer-head combinations (L11-H7, L10-H1, L9-H7, L9-H1, L8-H6).
* Axes: Labeled "K" (Key) horizontally and "Q" (Query) vertically with arrows indicating direction.
* **Bottom-Right:**
* Label: "Sparse GPT-2"
* Text Sequence: "The opposite of 'large' is 'brackets'" with numerical positions 1 to 8 below each word.
* Callouts: Stacked boxes indicating the words "opposite", "large", and "brackets" are modulated by specific layers:
* "opposite" (layer 0-1)
* "large" (layer 0-3)
* "brackets" (layer 0-10)
* Callout: "Modulated at 80% by" pointing to "small" (layer 12)
### Detailed Analysis
* **GPT-2 Attention Patterns:** The grid on the left shows a complex pattern of attention. Vertical blue lines suggest some heads attend strongly to specific positions across multiple layers. Red squares indicate focused attention at particular layer-head-position combinations.
* **Sparse GPT-2 Attention Heads:** The five grids at the top-right show specific attention patterns where key position 5 maps to query position 8.
* L11-H7: A red square at approximately (5,8) and a blue square at approximately (5,7).
* L10-H1: A red square at approximately (5,8).
* L9-H7: A red square at approximately (5,8).
* L9-H1: A red square at approximately (5,8) and a blue square at approximately (5,7).
* L8-H6: A red square at approximately (5,8).
* **Modulation:** The word "small" in layer 12 modulates the attention at 80%.
### Key Observations
* The Sparse GPT-2 model focuses attention on specific key-query relationships, as demonstrated by the highlighted heads mapping key position 5 to query position 8.
* Different layers are responsible for modulating different words in the sequence.
* The attention patterns in GPT-2 are more distributed compared to the focused attention in Sparse GPT-2.
### Interpretation
The image illustrates the difference in attention mechanisms between a standard GPT-2 model and a Sparse GPT-2 model. The Sparse GPT-2 model appears to have a more targeted attention mechanism, focusing on specific key-query relationships. The modulation of specific words by different layers suggests a hierarchical processing of the input sequence, where different layers are responsible for different aspects of understanding the context. The 80% modulation by "small" in layer 12 indicates that this layer plays a significant role in determining the relationship between the words in the sequence, specifically in the context of mapping key position 5 to query position 8.