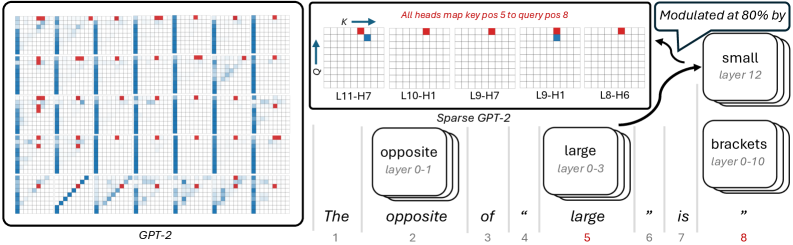
## Diagram: Attention Pattern Comparison (GPT-2 vs. Sparse GPT-2)
### Overview
The image is a technical diagram comparing the attention head patterns of a standard GPT-2 model (left panel) and a "Sparse GPT-2" model (right panel). It visualizes how different attention heads in various layers map key positions to query positions for a specific input sentence. The diagram includes a main heatmap-style grid, a detailed breakout of specific heads, and a flow diagram linking words to model layers.
### Components/Axes
**Left Panel (GPT-2):**
* **Label:** "GPT-2" (bottom center).
* **Grid:** A 12x12 grid representing attention heads (likely layers x heads or a similar mapping). The grid contains colored squares.
* **Color Legend (Implied):** Blue and red squares. The right panel clarifies that red indicates a specific mapping.
**Right Panel (Sparse GPT-2):**
* **Label:** "Sparse GPT-2" (bottom center).
* **Top Annotation:** "All heads map key pos 5 to query pos 8" (red text, top center).
* **Axes:** A small coordinate system in the top-left corner with:
* Vertical axis labeled "Q" (Query) with an upward arrow.
* Horizontal axis labeled "K" (Key) with a rightward arrow.
* **Grids:** Five smaller 12x12 grids arranged horizontally, each labeled with a specific attention head:
* L11-H7 (Layer 11, Head 7)
* L10-H1 (Layer 10, Head 1)
* L9-H7 (Layer 9, Head 7)
* L9-H1 (Layer 9, Head 1)
* L8-H6 (Layer 8, Head 6)
* **Legend/Key:** A red square and a blue square in the top-left grid (L11-H7). The annotation confirms red squares represent the mapping from key position 5 to query position 8.
* **Flow Diagram Components:**
* **Input Sentence:** "The opposite of \" large \" is \" \"" with positional indices 1 through 8 below each token. The word "large" (position 5) is highlighted in red.
* **Word Boxes:** Three rounded rectangles representing words and their associated layer ranges:
* "opposite" / "layer 0-1"
* "large" / "layer 0-3"
* "brackets" / "layer 0-10"
* **Modulation Box:** A box labeled "small" / "layer 12" with an arrow pointing to the "large" box, annotated with "Modulated at 80% by".
* **Connecting Lines:** Lines connect the words in the sentence to their respective boxes and show the flow of information/modulation.
### Detailed Analysis
**1. GPT-2 Attention Grid (Left Panel):**
* **Visual Trend:** The grid shows a pattern of vertical blue lines and scattered red squares. The blue lines suggest consistent attention patterns across certain positions for many heads. The red squares, representing the specific mapping from key pos 5 to query pos 8, are distributed across various heads without a single dominant pattern.
**2. Sparse GPT-2 Attention Grids (Right Panel - Top):**
* **Trend Verification:** For the five highlighted heads (L11-H7, L10-H1, L9-H7, L9-H1, L8-H6), the red squares (mapping K5->Q8) are consistently present. Their placement varies slightly but is generally in the upper-right quadrant of each head's grid.
* **Data Points (Approximate Grid Coordinates for Red Square):**
* L11-H7: (Q≈9, K≈5)
* L10-H1: (Q≈9, K≈5)
* L9-H7: (Q≈9, K≈5)
* L9-H1: (Q≈9, K≈5)
* L8-H6: (Q≈9, K≈5)
* **Observation:** The red squares are highly aligned across these specific heads in the Sparse model, indicating a focused, shared attention mechanism on the target position pair (5->8).
**3. Flow Diagram (Right Panel - Bottom):**
* **Component Isolation:**
* **Header/Context:** The sentence "The opposite of \" large \" is \" \"" defines the input. Token 5 ("large") is the focal key position.
* **Main Processing Flow:** The word "opposite" is processed in early layers (0-1). The word "large" is processed across layers 0-3. The word "brackets" (likely referring to the quotation marks) is processed across a wide range of layers (0-10).
* **Modulation:** A separate "small" component in layer 12 modulates the processing of "large" at an 80% rate. This suggests a late-layer, high-influence adjustment.
### Key Observations
1. **Focused vs. Distributed Attention:** The standard GPT-2 shows a distributed pattern for the K5->Q8 mapping (red squares scattered). The Sparse GPT-2 shows a highly concentrated pattern for the same mapping across the five highlighted heads.
2. **Layer Specialization:** The flow diagram indicates different words are active in different layer ranges. "Brackets" have the widest layer engagement (0-10), while "opposite" is limited to the earliest layers (0-1).
3. **Late-Stage Modulation:** A significant modulation (80%) occurs at the final layer (12) specifically targeting the processing of the word "large".
4. **Positional Consistency:** In the Sparse GPT-2 heads shown, the red square (K5->Q8) appears at a consistent relative position within each head's grid (around Q=9, K=5).
### Interpretation
This diagram illustrates a key difference in how sparse attention models can function compared to standard transformers. The data suggests that **Sparse GPT-2 achieves efficiency by forcing multiple attention heads across different layers to specialize in the same critical token-to-token mapping** (here, connecting the key at position 5 ["large"] to the query at position 8). This creates a robust, redundant pathway for that specific linguistic relationship.
In contrast, the standard GPT-2's attention for the same mapping is more diffuse, spread across many heads without strong consensus. The flow diagram provides a mechanistic hypothesis: early layers handle basic word relationships ("opposite"), mid-layers process core semantic content ("large"), and a late, powerful modulation (80% from "small" layer 12) fine-tunes the output based on that core content. The wide layer engagement for "brackets" suggests punctuation or structural tokens require sustained processing throughout the network.
The **outlier** is the "brackets" component, which has an unusually broad layer range (0-10), indicating that syntactic or structural elements may be processed in a fundamentally different, more persistent manner than content words. The **notable trend** is the engineered sparsity leading to head specialization, which is the core concept the diagram aims to demonstrate.