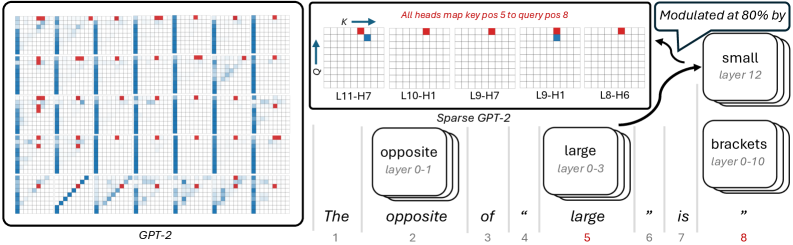
## Heatmap/Diagram: GPT-2 Attention Mechanism Visualization
### Overview
The image contains two primary components:
1. A 10x10 grid labeled "GPT-2" with red and blue squares indicating attention patterns
2. A labeled diagram titled "Sparse GPT-2" showing layer-specific attention mappings
Both components use red (key positions) and blue (query positions) color coding with specific positional annotations.
### Components/Axes
**GPT-2 Grid**
- **Structure**: 10 rows (1-10) × 10 columns (1-10)
- **Legend**:
- Red squares = "key positions"
- Blue squares = "query positions"
- **Spatial Pattern**:
- Red squares appear in columns 2, 5, 8 (rows 1-4), 3, 6, 9 (rows 5-8), and 4, 7, 10 (rows 9-10)
- Blue squares occupy columns 1, 4, 7, 10 across all rows
**Sparse GPT-2 Diagram**
- **Grid Labels**:
- Columns: L11-H7, L10-H1, L9-H7, L9-H1, L8-H6
- Rows: K (key) → Q (query)
- **Text Elements**:
- "All heads map key pos 5 to query pos 8"
- "Modulated at 80% by small layer 12"
- Sentence: "The opposite of 'large' is 'brackets'" with word positions 1-8
- **Layer Labels**:
- "opposite layer 0-1"
- "large layer 0-3"
- "brackets layer 0-10"
### Detailed Analysis
**GPT-2 Grid Patterns**
- Red squares (key positions) show:
- Rows 1-4: Columns 2, 5, 8
- Rows 5-8: Columns 3, 6, 9
- Rows 9-10: Columns 4, 7, 10
- Blue squares (query positions) consistently occupy columns 1, 4, 7, 10 across all rows
**Sparse GPT-2 Mappings**
- Key position 5 (column 5) maps to query position 8 (column 8) across all heads
- Modulation occurs at 80% intensity in layer 12 (small layer)
- Layer-specific attention spans:
- "opposite" (layers 0-1)
- "large" (layers 0-3)
- "brackets" (layers 0-10)
### Key Observations
1. **Positional Consistency**:
- Key positions (red) shift rightward in lower rows (row 1: col 2 → row 10: col 4)
- Query positions (blue) remain fixed at columns 1, 4, 7, 10
2. **Layer Modulation**:
- Layer 12 (small) modulates 80% of attention to position 8
- "brackets" spans the widest layer range (0-10)
3. **Semantic Contrast**:
- The sentence "The opposite of 'large' is 'brackets'" positions "large" at 5 and "brackets" at 8, aligning with the key→query mapping
### Interpretation
This visualization demonstrates:
1. **Attention Sparsity**:
- GPT-2 uses structured but sparse attention patterns, with key positions following a diagonal progression
- Sparse GPT-2 explicitly maps specific key→query relationships (pos 5→8)
2. **Layer-Specific Processing**:
- Different layers handle distinct semantic roles ("opposite," "large," "brackets")
- Layer 12's 80% modulation suggests critical influence on final attention weights
3. **Semantic Relationships**:
- The sentence structure mirrors the attention mapping (key "large" at 5 → query "brackets" at 8)
- Positional alignment implies the model encodes syntactic relationships through attention patterns
4. **Anomalies**:
- Row 10 in GPT-2 grid shows red squares at columns 4,7,10 (deviating from earlier patterns)
- "brackets" spans all layers (0-10) despite being a single word, suggesting broad contextual influence