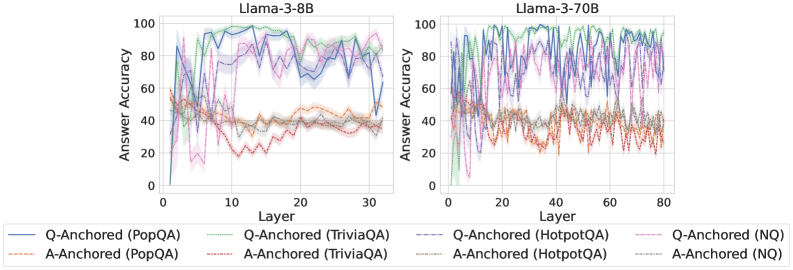
## Line Charts: Llama-3-8B and Llama-3-70B Answer Accuracy vs. Layer
### Overview
The image presents two line charts comparing the answer accuracy of Llama-3-8B and Llama-3-70B models across different layers for various question-answering datasets. The charts depict the performance of both "Q-Anchored" and "A-Anchored" approaches on PopQA, TriviaQA, HotpotQA, and NQ datasets. The x-axis represents the layer number, while the y-axis represents the answer accuracy.
### Components/Axes
**Left Chart (Llama-3-8B):**
* **Title:** Llama-3-8B
* **X-axis:** Layer, with markers at 0, 10, 20, and 30.
* **Y-axis:** Answer Accuracy, ranging from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100.
**Right Chart (Llama-3-70B):**
* **Title:** Llama-3-70B
* **X-axis:** Layer, with markers at 0, 20, 40, 60, and 80.
* **Y-axis:** Answer Accuracy, ranging from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100.
**Legend (Located at the bottom of both charts):**
* **Q-Anchored (PopQA):** Solid Blue Line
* **A-Anchored (PopQA):** Dashed Brown Line
* **Q-Anchored (TriviaQA):** Dotted Green Line
* **A-Anchored (TriviaQA):** Dash-Dot Green Line
* **Q-Anchored (HotpotQA):** Dash-Dot Purple Line
* **A-Anchored (HotpotQA):** Dotted Red Line
* **Q-Anchored (NQ):** Dashed Purple Line
* **A-Anchored (NQ):** Dash-Dot Brown Line
### Detailed Analysis
**Llama-3-8B:**
* **Q-Anchored (PopQA):** (Solid Blue) Starts around 60% accuracy at layer 0, drops slightly, then rises sharply to fluctuate between 80% and 100% from layer 10 onwards.
* **A-Anchored (PopQA):** (Dashed Brown) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts around 60% accuracy, drops slightly, then rises sharply to fluctuate between 70% and 90% from layer 10 onwards.
* **A-Anchored (TriviaQA):** (Dash-Dot Green) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
* **Q-Anchored (HotpotQA):** (Dash-Dot Purple) Starts around 60% accuracy, drops sharply, then rises sharply to fluctuate between 70% and 90% from layer 10 onwards.
* **A-Anchored (HotpotQA):** (Dotted Red) Starts around 50% accuracy, decreases sharply, and then stabilizes around 30% from layer 10 onwards.
* **Q-Anchored (NQ):** (Dashed Purple) Starts around 60% accuracy, drops sharply, then rises sharply to fluctuate between 70% and 90% from layer 10 onwards.
* **A-Anchored (NQ):** (Dash-Dot Brown) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
**Llama-3-70B:**
* **Q-Anchored (PopQA):** (Solid Blue) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 80% to 100% from layer 10 onwards.
* **A-Anchored (PopQA):** (Dashed Brown) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
* **Q-Anchored (TriviaQA):** (Dotted Green) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 80% to 100% from layer 10 onwards.
* **A-Anchored (TriviaQA):** (Dash-Dot Green) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
* **Q-Anchored (HotpotQA):** (Dash-Dot Purple) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 70% to 90% from layer 10 onwards.
* **A-Anchored (HotpotQA):** (Dotted Red) Starts around 50% accuracy, decreases sharply, and then stabilizes around 30% from layer 10 onwards.
* **Q-Anchored (NQ):** (Dashed Purple) Starts around 60% accuracy, fluctuates significantly, and then stabilizes around 70% to 90% from layer 10 onwards.
* **A-Anchored (NQ):** (Dash-Dot Brown) Starts around 50% accuracy, decreases slightly, and then stabilizes around 40% from layer 10 onwards.
### Key Observations
* For both models, "Q-Anchored" approaches generally achieve higher answer accuracy than "A-Anchored" approaches across all datasets.
* The "Q-Anchored" lines show a sharp increase in accuracy around layer 10 for Llama-3-8B, while Llama-3-70B fluctuates more.
* The "A-Anchored" lines tend to stabilize around 40% accuracy after the initial layers for both models, except for HotpotQA, which stabilizes around 30%.
* Llama-3-70B has a longer x-axis, indicating more layers than Llama-3-8B.
### Interpretation
The data suggests that anchoring the question (Q-Anchored) leads to better performance in question-answering tasks compared to anchoring the answer (A-Anchored) for both Llama-3-8B and Llama-3-70B models. The initial layers seem to be crucial for the "Q-Anchored" approaches, as they exhibit a significant increase in accuracy around layer 10. The larger model, Llama-3-70B, shows more fluctuation in accuracy across layers, potentially indicating a more complex learning process. The consistent performance of "A-Anchored" approaches around 40% suggests a baseline level of accuracy that is independent of the number of layers. The lower accuracy of "A-Anchored (HotpotQA)" might indicate that HotpotQA is a more challenging dataset for this approach.