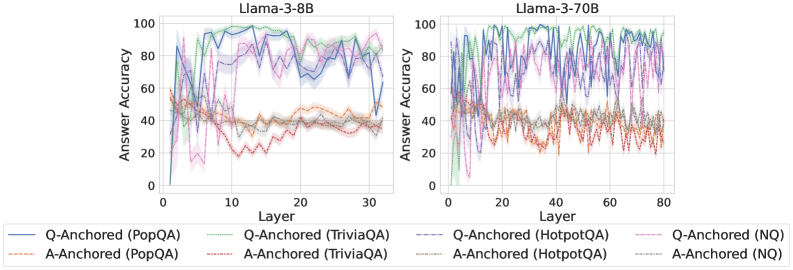
## Line Graph: Answer Accuracy Across Model Layers for Llama-3-8B and Llama-3-70B
### Overview
The image contains two side-by-side line graphs comparing answer accuracy across transformer model layers for two Llama-3 variants (8B and 70B parameters). Each graph tracks six distinct data series representing different anchoring methods (Q-Anchored/A-Anchored) across four datasets (PopQA, TriviaQA, HotpotQA, NQ). The graphs show significant variability in accuracy across layers, with notable differences between model sizes.
### Components/Axes
- **X-axis (Layer)**:
- Llama-3-8B: 0–30 (discrete increments)
- Llama-3-70B: 0–80 (discrete increments)
- **Y-axis (Answer Accuracy)**: 0–100% (continuous scale)
- **Legends**:
- Position: Bottom of both charts
- Entries (color/style):
1. Q-Anchored (PopQA): Solid blue
2. Q-Anchored (TriviaQA): Dotted green
3. Q-Anchored (HotpotQA): Dashed purple
4. Q-Anchored (NQ): Dotted pink
5. A-Anchored (PopQA): Dashed orange
6. A-Anchored (TriviaQA): Dotted gray
7. A-Anchored (HotpotQA): Dashed red
8. A-Anchored (NQ): Dotted brown
### Detailed Analysis
#### Llama-3-8B (Left Chart)
- **Q-Anchored (PopQA)**: Peaks at ~90% accuracy in layer 10, drops to ~40% by layer 30 with high volatility.
- **A-Anchored (PopQA)**: Starts at ~50%, fluctuates between 30–60% with sharp dips (e.g., layer 15: ~20%).
- **Q-Anchored (TriviaQA)**: Stable ~70–80% until layer 20, then erratic (60–90%).
- **A-Anchored (TriviaQA)**: Gradual decline from ~60% to ~40% with oscillations.
- **Q-Anchored (HotpotQA)**: Sharp initial drop from ~80% to ~50% by layer 10, then stabilizes ~60–70%.
- **A-Anchored (HotpotQA)**: Starts ~70%, declines to ~40% by layer 30 with jagged patterns.
- **Q-Anchored (NQ)**: Peaks ~95% at layer 5, crashes to ~30% by layer 30.
- **A-Anchored (NQ)**: Starts ~60%, declines to ~20% with irregular fluctuations.
#### Llama-3-70B (Right Chart)
- **Q-Anchored (PopQA)**: Starts ~85%, stabilizes ~70–80% after layer 20.
- **A-Anchored (PopQA)**: Starts ~60%, stabilizes ~50–60% after layer 40.
- **Q-Anchored (TriviaQA)**: Peaks ~90% at layer 10, declines to ~70% by layer 80.
- **A-Anchored (TriviaQA)**: Starts ~70%, declines to ~50% with moderate volatility.
- **Q-Anchored (HotpotQA)**: Starts ~80%, stabilizes ~65–75% after layer 30.
- **A-Anchored (HotpotQA)**: Starts ~75%, declines to ~50% with oscillations.
- **Q-Anchored (NQ)**: Peaks ~95% at layer 5, declines to ~60% by layer 80.
- **A-Anchored (NQ)**: Starts ~65%, declines to ~40% with irregular drops.
### Key Observations
1. **Model Size Impact**: Llama-3-70B shows more stable accuracy trends compared to Llama-3-8B, particularly in later layers.
2. **Anchoring Method Differences**:
- Q-Anchored methods generally outperform A-Anchored in early layers but show diminishing returns in larger models.
- A-Anchored methods exhibit greater volatility in smaller models (8B).
3. **Dataset Variability**:
- NQ (Natural Questions) shows the most dramatic drops in accuracy across both models.
- PopQA maintains higher baseline accuracy than TriviaQA/HotpotQA in later layers.
4. **Layer-Specific Anomalies**:
- Layer 5 in Llama-3-8B (Q-Anchored NQ) shows an outlier peak at ~95%.
- Layer 30 in Llama-3-8B (A-Anchored PopQA) has a sharp dip to ~20%.
### Interpretation
The data suggests that model size (70B vs. 8B) correlates with improved stability in answer accuracy across layers, particularly for Q-Anchored methods. However, anchoring effectiveness varies significantly by dataset:
- **PopQA** benefits most from Q-Anchoring in smaller models but shows diminishing returns in larger models.
- **NQ** exhibits the most instability, with Q-Anchored methods collapsing in later layers despite initial promise.
- The A-Anchored methods' volatility in the 8B model implies architectural limitations in smaller transformers for maintaining consistent reasoning chains.
These patterns highlight the importance of dataset-specific anchoring strategies and suggest that larger models may better preserve Q-Anchored performance but still struggle with dataset heterogeneity. The sharp declines in NQ accuracy across all layers warrant further investigation into question complexity and model attention mechanisms.