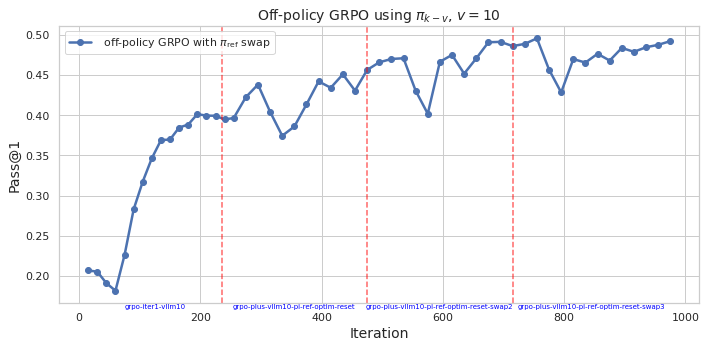
## Line Chart: Off-policy GRPO using π_{k−v}, v = 10
### Overview
The chart illustrates the performance of an off-policy GRPO algorithm with π_ref swap over 1000 iterations. The y-axis measures "Pass@1" (a metric likely representing task success rate), while the x-axis tracks iterations. A blue line represents the algorithm's performance, with red dashed vertical lines marking specific iteration milestones.
### Components/Axes
- **X-axis (Iteration)**: Ranges from 0 to 1000, with labeled milestones at 200, 400, 600, and 800.
- **Y-axis (Pass@1)**: Scaled from 0.20 to 0.50 in increments of 0.05.
- **Legend**: Located in the top-left corner, labeled "off-policy GRPO with π_ref swap" (blue line).
- **Red Dashed Lines**: Vertical markers at iterations 200, 400, 600, and 800.
### Detailed Analysis
- **Initial Phase (0–200 iterations)**: The blue line starts at ~0.20, sharply rising to ~0.35 by iteration 100, then plateauing near 0.40 by iteration 200.
- **Mid-Phase (200–600 iterations)**: A dip to ~0.37 occurs around iteration 400, followed by recovery to ~0.45 by iteration 600.
- **Late Phase (600–1000 iterations)**: Performance stabilizes between ~0.45 and ~0.49, with minor fluctuations. The final value at iteration 1000 is ~0.49.
### Key Observations
1. **General Trend**: Pass@1 improves monotonically from ~0.20 to ~0.49 over 1000 iterations.
2. **Milestone Markers**: Red dashed lines at 200, 400, 600, and 800 may indicate algorithmic adjustments (e.g., parameter resets or reference policy swaps).
3. **Fluctuations**: Temporary dips (e.g., ~0.37 at iteration 400) suggest instability during parameter changes, but recovery occurs afterward.
4. **Final Performance**: The algorithm achieves ~0.49 Pass@1 by iteration 1000, indicating strong convergence.
### Interpretation
The chart demonstrates that the off-policy GRPO algorithm with π_ref swap improves task performance (Pass@1) over time, with a ~145% increase from initial to final iterations. The red dashed lines likely correspond to critical algorithmic interventions (e.g., reference policy updates or optimization resets), which temporarily disrupt performance but ultimately contribute to long-term gains. The dip at iteration 400 highlights the trade-off between exploration (via π_ref swaps) and stability, while the final convergence suggests effective adaptation to the task. The algorithm’s robustness is evident in its ability to recover from mid-phase instability and maintain high performance in later iterations.