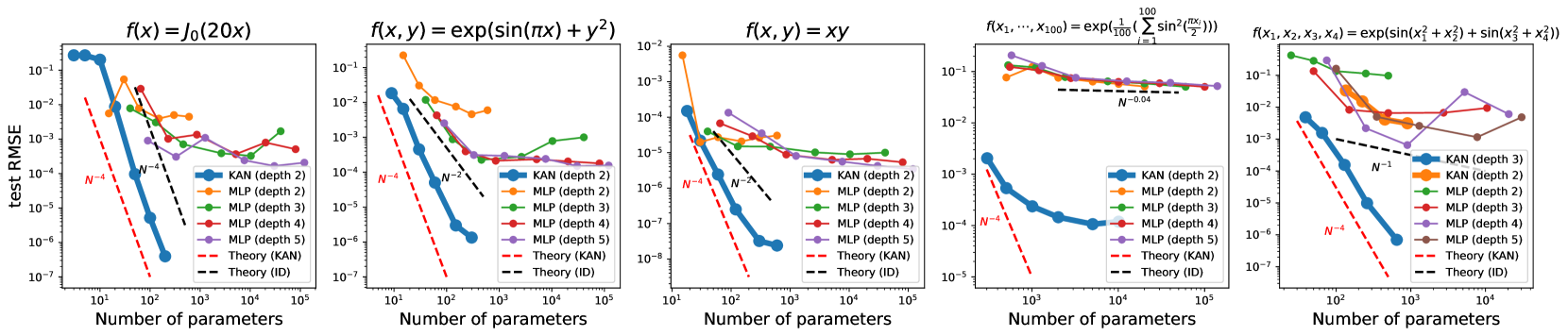
# Technical Document Extraction: Test RMSE vs. Number of Parameters
## Overview
The image contains five subplots comparing the **test RMSE** (Root Mean Square Error) of different neural network architectures (KAN and MLP) across varying function complexities. Each subplot plots RMSE against the **number of parameters** (log scale) for different model depths. Theoretical convergence rates (e.g., \(N^{-4}\), \(N^{-2}\)) are indicated by dashed lines.
---
### Subplot 1: \(f(x) = J_0(20x)\)
- **X-axis**: Number of parameters (log scale: \(10^1\) to \(10^5\))
- **Y-axis**: Test RMSE (log scale: \(10^{-1}\) to \(10^{-7}\))
- **Legend**:
- **KAN (depth 2)**: Blue line (solid)
- **MLP (depth 2)**: Orange line (solid)
- **MLP (depth 3)**: Green line (solid)
- **MLP (depth 4)**: Red line (solid)
- **MLP (depth 5)**: Purple line (solid)
- **Theory (KAN)**: Red dashed line (\(N^{-4}\))
- **Theory (ID)**: Black dashed line (\(N^{-4}\))
- **Key Trends**:
- KAN (depth 2) closely follows the \(N^{-4}\) theoretical trend.
- MLP models (depths 2–5) show slower convergence, with RMSE plateauing at higher parameter counts.
- Theory (ID) aligns with KAN's performance.
---
### Subplot 2: \(f(x, y) = \exp(\sin(\pi x) + y^2)\)
- **X-axis**: Number of parameters (log scale: \(10^1\) to \(10^5\))
- **Y-axis**: Test RMSE (log scale: \(10^{-1}\) to \(10^{-7}\))
- **Legend**:
- **KAN (depth 2)**: Blue line (solid)
- **MLP (depth 2)**: Orange line (solid)
- **MLP (depth 3)**: Green line (solid)
- **MLP (depth 4)**: Red line (solid)
- **MLP (depth 5)**: Purple line (solid)
- **Theory (KAN)**: Red dashed line (\(N^{-4}\))
- **Theory (ID)**: Black dashed line (\(N^{-2}\))
- **Key Trends**:
- KAN (depth 2) follows \(N^{-4}\) theory but deviates at higher parameters.
- MLP (depth 5) outperforms shallower MLPs, approaching \(N^{-2}\) theory.
- Theory (ID) (\(N^{-2}\)) aligns with MLP (depth 5) at large parameter counts.
---
### Subplot 3: \(f(x, y) = xy\)
- **X-axis**: Number of parameters (log scale: \(10^1\) to \(10^5\))
- **Y-axis**: Test RMSE (log scale: \(10^{-2}\) to \(10^{-8}\))
- **Legend**:
- **KAN (depth 2)**: Blue line (solid)
- **MLP (depth 2)**: Orange line (solid)
- **MLP (depth 3)**: Green line (solid)
- **MLP (depth 4)**: Red line (solid)
- **MLP (depth 5)**: Purple line (solid)
- **Theory (KAN)**: Red dashed line (\(N^{-4}\))
- **Theory (ID)**: Black dashed line (\(N^{-2}\))
- **Key Trends**:
- KAN (depth 2) closely matches \(N^{-4}\) theory.
- MLP (depth 5) converges to \(N^{-2}\) theory at large parameter counts.
- All models show improved RMSE with increasing parameters.
---
### Subplot 4: \(f(x_1, \dots, x_{100}) = \exp\left(\frac{1}{100} \sum_{i=1}^{100} \sin^2\left(\frac{\pi x_i}{2}\right)\right)\)
- **X-axis**: Number of parameters (log scale: \(10^3\) to \(10^5\))
- **Y-axis**: Test RMSE (log scale: \(10^{-1}\) to \(10^{-5}\))
- **Legend**:
- **KAN (depth 2)**: Blue line (solid)
- **MLP (depth 2)**: Orange line (solid)
- **MLP (depth 3)**: Green line (solid)
- **MLP (depth 4)**: Red line (solid)
- **MLP (depth 5)**: Purple line (solid)
- **Theory (KAN)**: Red dashed line (\(N^{-4}\))
- **Theory (ID)**: Black dashed line (\(N^{-0.04}\))
- **Key Trends**:
- KAN (depth 2) follows \(N^{-4}\) theory but underperforms at \(10^5\) parameters.
- MLP models (depths 2–5) show minimal improvement, with RMSE plateauing near \(10^{-4}\).
- Theory (ID) (\(N^{-0.04}\)) suggests near-linear convergence.
---
### Subplot 5: \(f(x_1, x_2, x_3, x_4) = \exp(\sin(x_1^2 + x_2^2) + \sin(x_3^2 + x_4^2)\)
- **X-axis**: Number of parameters (log scale: \(10^1\) to \(10^5\))
- **Y-axis**: Test RMSE (log scale: \(10^{-1}\) to \(10^{-7}\))
- **Legend**:
- **KAN (depth 2)**: Blue line (solid)
- **MLP (depth 2)**: Orange line (solid)
- **MLP (depth 3)**: Green line (solid)
- **MLP (depth 4)**: Red line (solid)
- **MLP (depth 5)**: Purple line (solid)
- **Theory (KAN)**: Red dashed line (\(N^{-4}\))
- **Theory (ID)**: Black dashed line (\(N^{-2}\))
- **Key Trends**:
- KAN (depth 2) follows \(N^{-4}\) theory but deviates at higher parameters.
- MLP (depth 5) outperforms shallower MLPs, approaching \(N^{-2}\) theory.
- Theory (ID) (\(N^{-2}\)) aligns with MLP (depth 5) at large parameter counts.