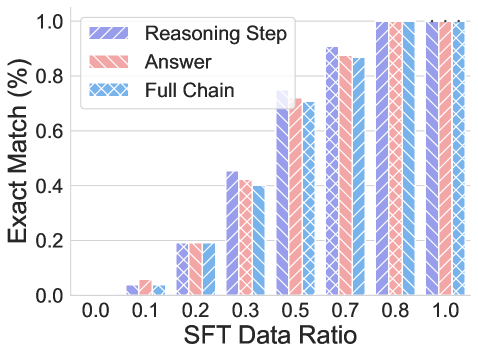
## Bar Chart: Exact Match Performance vs SFT Data Ratio
### Overview
The chart compares the performance of three model components (Reasoning Step, Answer, Full Chain) across varying SFT Data Ratios (0.0 to 1.0). Performance is measured as Exact Match percentage, with all components showing increasing effectiveness as data ratio increases.
### Components/Axes
- **X-axis**: SFT Data Ratio (0.0, 0.1, 0.2, 0.3, 0.5, 0.7, 0.8, 1.0)
- **Y-axis**: Exact Match (%) (0.0 to 1.0 in 0.2 increments)
- **Legend**:
- Purple (Reasoning Step)
- Red (Answer)
- Blue (Full Chain)
- **Bar Groups**: Three bars per data ratio (purple, red, blue)
### Detailed Analysis
1. **0.0 Ratio**:
- All components near 0% (purple: ~0.03, red: ~0.05, blue: ~0.02)
2. **0.1 Ratio**:
- Reasoning Step (~0.05) > Answer (~0.03) > Full Chain (~0.02)
3. **0.2 Ratio**:
- All ~0.2% (purple: 0.2, red: 0.2, blue: 0.2)
4. **0.3 Ratio**:
- Reasoning Step (~0.45) > Answer (~0.4) > Full Chain (~0.38)
5. **0.5 Ratio**:
- All ~0.7% (purple: 0.7, red: 0.7, blue: 0.7)
6. **0.7 Ratio**:
- All ~0.9% (purple: 0.9, red: 0.88, blue: 0.87)
7. **0.8 Ratio**:
- All reach 1.0% (purple: 1.0, red: 1.0, blue: 1.0)
8. **1.0 Ratio**:
- All maintain 1.0% (purple: 1.0, red: 1.0, blue: 1.0)
### Key Observations
- **Consistent Growth**: All components show near-linear improvement with increasing data ratio.
- **Full Chain Performance**: Slightly lags behind Reasoning Step and Answer at lower ratios (0.3) but matches them at higher ratios.
- **Saturation Point**: All components achieve 100% exact match at 0.8+ data ratio.
- **Color Consistency**: Legend colors perfectly match bar colors (purple/red/blue).
### Interpretation
The data demonstrates that model performance scales predictably with training data volume. The "Full Chain" component (likely an integrated system) matches the performance of individual components (Reasoning Step and Answer) at higher data ratios, suggesting effective integration. The minor performance gap at 0.3 ratio may indicate data sparsity challenges or architectural limitations in early training stages. The saturation at 0.8 ratio implies diminishing returns beyond this point, making 0.8+ ratios optimal for deployment.