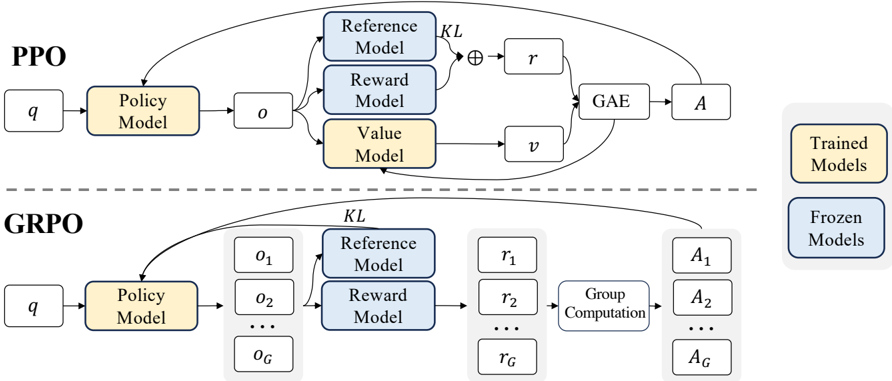
## Diagram: Comparison of PPO and GRPO Algorithms
### Overview
The diagram illustrates the architectural differences between Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) in reinforcement learning. It highlights the flow of data, model interactions, and computational steps for each algorithm.
### Components/Axes
- **Key Components**:
- **Policy Model**: Generates actions (`o`) from input (`q`).
- **Reference Model**: Provides a baseline for comparison (frozen in both PPO and GRPO).
- **Reward Model**: Computes rewards (`r` or `r1...rG`) (frozen in GRPO, trained in PPO).
- **Value Model**: Estimates state values (`v`) (trained in PPO only).
- **GAE (Generalized Advantage Estimation)**: Combines KL divergence and reward signals to compute advantages (`A`).
- **Group Computation**: Aggregates rewards (`r1...rG`) into a group action (`AG`) for GRPO.
- **Legend**:
- **Trained Models** (yellow): Policy, Reward, Value Models (PPO) and Policy Model (GRPO).
- **Frozen Models** (blue): Reference and Reward Models (GRPO).
### Detailed Analysis
1. **PPO Workflow**:
- Input `q` → Policy Model → Output `o`.
- `o` is processed by:
- Reference Model (frozen, blue).
- Reward Model (trained, yellow).
- Value Model (trained, yellow).
- Outputs feed into GAE, which computes advantage `A`.
2. **GRPO Workflow**:
- Input `q` → Policy Model → Multiple outputs (`o1...oG`).
- Each `oi` is processed by:
- Reference Model (frozen, blue).
- Reward Model (frozen, blue).
- Rewards (`r1...rG`) are aggregated via Group Computation to produce `AG`.
### Key Observations
- **Model Training Status**:
- PPO trains Policy, Reward, and Value Models (yellow).
- GRPO freezes Reference and Reward Models (blue) but trains the Policy Model (yellow).
- **Output Handling**:
- PPO uses a single output (`o`) for advantage computation.
- GRPO processes multiple outputs (`o1...oG`) and aggregates rewards into a group action (`AG`).
- **Computational Steps**:
- PPO relies on GAE for advantage estimation.
- GRPO uses Group Computation to handle multi-output scenarios.
### Interpretation
- **PPO’s Strengths**:
- Trains multiple models (Policy, Reward, Value) for fine-grained policy updates.
- Uses GAE to balance exploration and exploitation via KL divergence and reward signals.
- **GRPO’s Innovations**:
- Freezes Reference and Reward Models to stabilize training.
- Processes multiple outputs (`o1...oG`) to handle complex, grouped actions (e.g., multi-step tasks).
- Group Computation enables efficient scaling for high-dimensional action spaces.
- **Trade-offs**:
- PPO’s training of Reward and Value Models may increase computational cost but improve policy adaptability.
- GRPO’s frozen models reduce training complexity but may limit reward signal flexibility.
This diagram underscores the design philosophies of PPO (dynamic, multi-model training) and GRPO (stability via frozen components with group-based optimization).