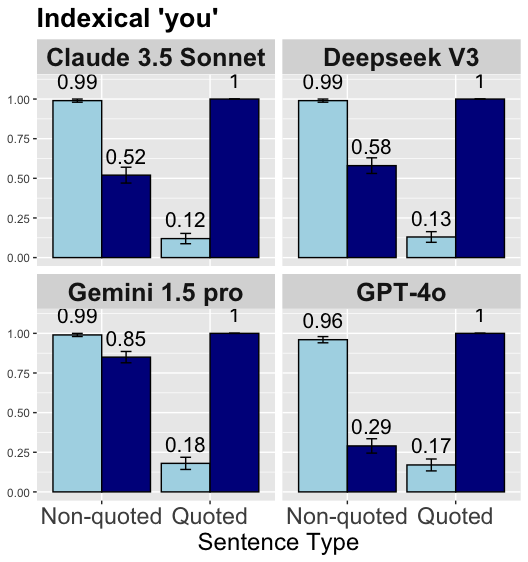
## Bar Chart: Indexical 'you'
### Overview
The image presents a bar chart comparing the performance of four language models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o) in handling indexical "you" in non-quoted and quoted sentences. The chart is divided into four subplots, one for each language model. Each subplot displays two pairs of bars, representing the model's performance on non-quoted and quoted sentences. The y-axis represents a score, ranging from 0.00 to 1.00. Error bars are included on each bar.
### Components/Axes
* **Title:** Indexical 'you'
* **X-axis:** Sentence Type (Categories: Non-quoted, Quoted)
* **Y-axis:** Score (Scale: 0.00, 0.25, 0.50, 0.75, 1.00)
* **Subplot Titles (Language Models):** Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, GPT-4o
* **Bar Colors:** Light Blue (Non-quoted), Dark Blue (Quoted)
* **Error Bars:** Present on each bar, indicating variability.
### Detailed Analysis
**Claude 3.5 Sonnet:**
* Non-quoted: Score of 0.99 with a small error bar.
* Quoted: Score of 0.12 with a small error bar.
**Deepseek V3:**
* Non-quoted: Score of 0.99 with a small error bar.
* Quoted: Score of 0.13 with a small error bar.
**Gemini 1.5 pro:**
* Non-quoted: Score of 0.99 with a small error bar.
* Quoted: Score of 0.18 with a small error bar.
**GPT-4o:**
* Non-quoted: Score of 0.96 with a small error bar.
* Quoted: Score of 0.17 with a small error bar.
### Key Observations
* All four language models perform very well (scores close to 1.00) on non-quoted sentences.
* All four language models perform significantly worse on quoted sentences.
* The error bars appear relatively small, suggesting consistent performance within each condition.
* The performance difference between quoted and non-quoted sentences is substantial for all models.
### Interpretation
The data suggests that all four language models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o) are much better at understanding and processing indexical "you" when it appears in non-quoted sentences compared to quoted sentences. This could be because the models are trained to recognize and handle direct speech more effectively, or because the context provided by the quotation marks helps the models to correctly interpret the meaning of "you." The consistent pattern across all four models indicates a general trend in how these models handle indexical references in different linguistic contexts. The high scores for non-quoted sentences suggest a strong capability in recognizing and processing direct speech, while the lower scores for quoted sentences highlight a potential area for improvement in understanding contextual references.