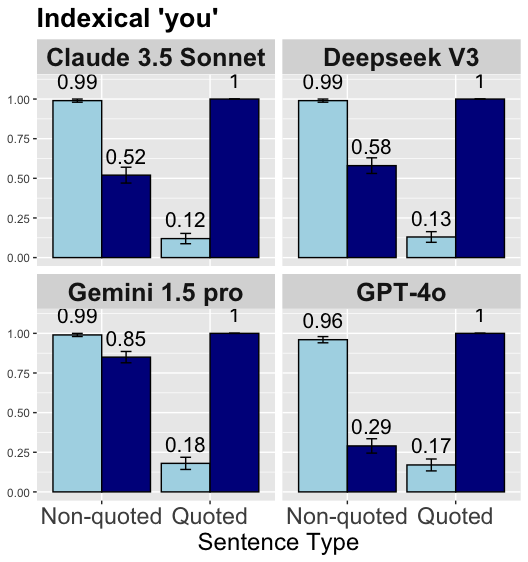
\n
## Bar Chart: Indexical 'you' Performance
### Overview
This image presents a bar chart comparing the performance of four large language models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o) on a task related to understanding the indexical pronoun "you". The performance is evaluated across two types of sentences: "Non-quoted" and "Quoted". Each bar represents the model's score, with error bars indicating the uncertainty.
### Components/Axes
* **Title:** "Indexical 'you'"
* **X-axis:** "Sentence Type" with categories "Non-quoted" and "Quoted".
* **Y-axis:** Scale ranging from 0.00 to 1.00, representing the performance score.
* **Models (Rows):**
* Claude 3.5 Sonnet
* Deepseek V3
* Gemini 1.5 pro
* GPT-4o
* **Bar Colors:**
* Light Blue: "Non-quoted" sentences
* Dark Blue: "Quoted" sentences
* **Error Bars:** Green horizontal lines indicating uncertainty around each score.
### Detailed Analysis
Let's analyze each model's performance:
**1. Claude 3.5 Sonnet:**
* **Non-quoted:** The light blue bar slopes upward to approximately 0.99, with an error bar extending from roughly 0.95 to 1.00.
* **Quoted:** The dark blue bar slopes upward to approximately 0.52, with an error bar extending from roughly 0.45 to 0.60.
**2. Deepseek V3:**
* **Non-quoted:** The light blue bar slopes upward to approximately 0.99, with an error bar extending from roughly 0.95 to 1.00.
* **Quoted:** The dark blue bar slopes upward to approximately 0.13, with an error bar extending from roughly 0.10 to 0.15.
**3. Gemini 1.5 pro:**
* **Non-quoted:** The light blue bar slopes upward to approximately 0.99, with an error bar extending from roughly 0.95 to 1.00.
* **Quoted:** The dark blue bar slopes upward to approximately 0.18, with an error bar extending from roughly 0.15 to 0.20.
**4. GPT-4o:**
* **Non-quoted:** The light blue bar slopes upward to approximately 0.96, with an error bar extending from roughly 0.92 to 1.00.
* **Quoted:** The dark blue bar slopes upward to approximately 0.17, with an error bar extending from roughly 0.15 to 0.20.
### Key Observations
* All models perform very well on "Non-quoted" sentences, achieving scores close to 1.00.
* There is a significant drop in performance for all models when dealing with "Quoted" sentences.
* Deepseek V3 exhibits the lowest performance on "Quoted" sentences (approximately 0.13).
* Claude 3.5 Sonnet shows the highest performance on "Quoted" sentences (approximately 0.52).
* The error bars suggest a relatively high degree of uncertainty, particularly for the "Quoted" sentence type.
### Interpretation
The data suggests that these large language models struggle with understanding the reference of the pronoun "you" when it appears within quoted speech. This is likely due to the complexities of tracking speaker identity and context shifts introduced by quotations. The models are highly proficient at understanding "you" in direct, non-quoted statements, but their performance degrades substantially when the pronoun's referent is ambiguous within a quoted context.
The differences in performance between the models on "Quoted" sentences indicate varying levels of robustness in handling contextual information and resolving coreference. Claude 3.5 Sonnet appears to be the most capable of handling this challenge, while Deepseek V3 is the least. The consistent high performance on "Non-quoted" sentences suggests that the core language understanding capabilities of these models are strong, but their ability to reason about discourse and speaker attribution requires further improvement. The error bars indicate that the observed differences in performance may not always be statistically significant, but the overall trend is clear: quoted speech poses a significant challenge for these models.