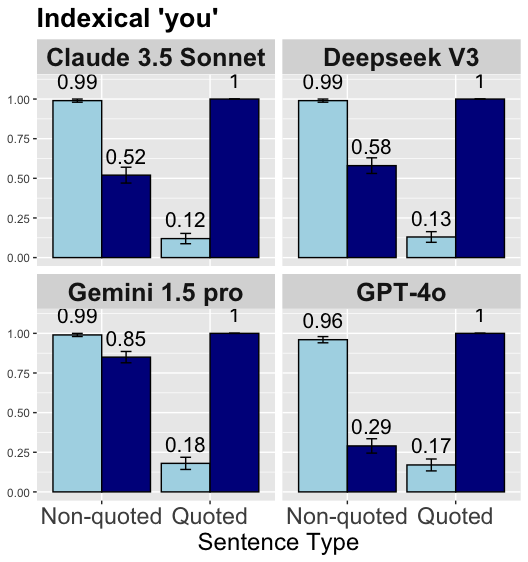
## Bar Chart: Indexical 'you' Performance Across Models and Sentence Types
### Overview
The image presents a bar chart comparing the performance of four language models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 Pro, GPT-4o) on two sentence types: "Non-quoted" and "Quoted." Each model is represented in a separate panel, with performance metrics (percentage) on the y-axis and sentence types on the x-axis. Error bars indicate uncertainty in measurements.
### Components/Axes
- **Title**: "Indexical 'you'" (top of the chart).
- **X-axis**: "Sentence Type" with categories "Non-quoted" and "Quoted."
- **Y-axis**: Performance metric (percentage, 0.00–1.00).
- **Legend**: Located in the top-left corner, indicating:
- Light blue: Non-quoted sentences.
- Dark blue: Quoted sentences.
- **Error Bars**: Gray lines above/below bars, representing uncertainty (e.g., ±0.01, ±0.03).
### Detailed Analysis
#### Claude 3.5 Sonnet
- **Non-quoted**: 0.99 (±0.01)
- **Quoted**: 0.52 (±0.12)
- **Error Bars**: Small for Non-quoted, larger for Quoted.
#### Deepseek V3
- **Non-quoted**: 0.99 (±0.01)
- **Quoted**: 0.58 (±0.13)
- **Error Bars**: Similar to Claude 3.5 Sonnet, with slightly larger uncertainty in Quoted.
#### Gemini 1.5 Pro
- **Non-quoted**: 0.99 (±0.01)
- **Quoted**: 0.85 (±0.18)
- **Error Bars**: Largest uncertainty in Quoted (0.18).
#### GPT-4o
- **Non-quoted**: 0.96 (±0.01)
- **Quoted**: 0.29 (±0.17)
- **Error Bars**: Highest uncertainty in Quoted (0.17).
### Key Observations
1. **Non-quoted performance**: All models achieve near-perfect scores (0.96–0.99), with minimal uncertainty (±0.01–0.03).
2. **Quoted performance**: Varies significantly:
- **Gemini 1.5 Pro** has the highest Quoted score (0.85) but the largest uncertainty (±0.18).
- **GPT-4o** has the lowest Quoted score (0.29) with high uncertainty (±0.17).
3. **Error bar trends**: Quoted values consistently show larger error bars than Non-quoted, suggesting greater variability in model performance for quoted sentences.
### Interpretation
The data indicates that all models perform exceptionally well on non-quoted sentences, likely due to clearer context or structure. However, quoted sentences introduce variability, with Gemini 1.5 Pro showing the best balance of high performance and moderate uncertainty, while GPT-4o struggles the most. The error bars highlight that quoted sentence analysis is less reliable across models, possibly due to ambiguity in quoted content or model-specific biases. This suggests that model robustness may depend on sentence structure, with quoted sentences posing a greater challenge.