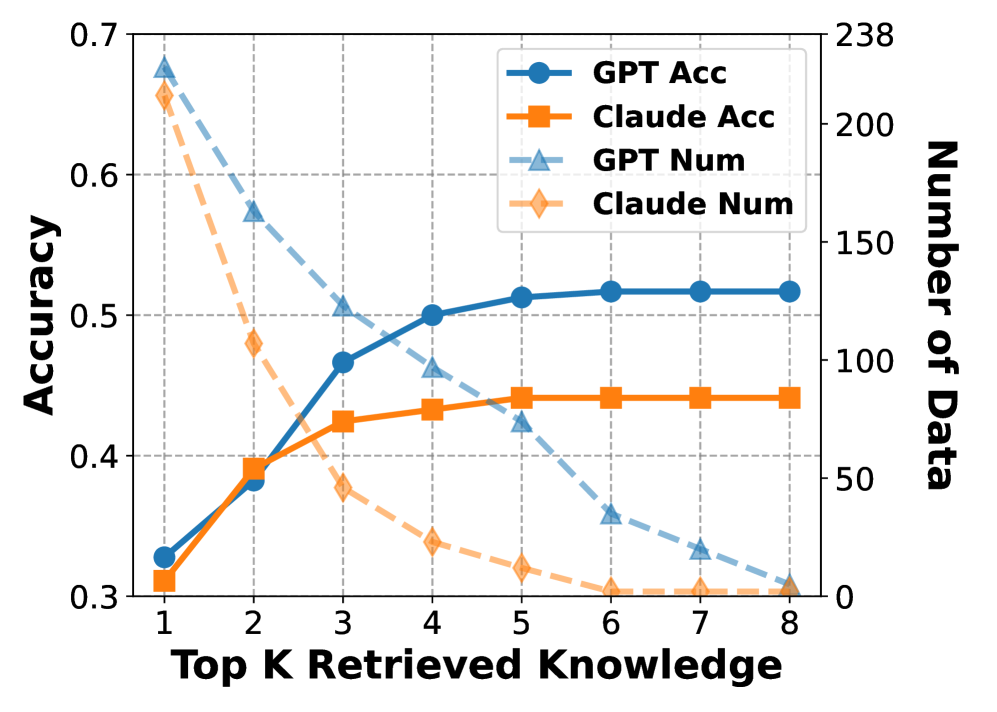
## Line Chart: Accuracy vs. Top K Retrieved Knowledge
### Overview
The chart compares the performance of two systems (GPT and Claude) across two metrics: **Accuracy** and **Number of Data Points**, as the number of retrieved knowledge items (Top K) increases from 1 to 8. Four data series are plotted:
- **GPT Accuracy** (blue circles)
- **Claude Accuracy** (orange squares)
- **GPT Number of Data Points** (blue triangles)
- **Claude Number of Data Points** (orange diamonds)
### Components/Axes
- **X-axis**: "Top K Retrieved Knowledge" (integer values 1–8)
- **Primary Y-axis (left)**: "Accuracy" (0.3–0.7)
- **Secondary Y-axis (right)**: "Number of Data" (0–238)
- **Legend**: Located in the top-right corner, with color/symbol mappings for all four data series.
### Detailed Analysis
1. **GPT Accuracy (blue circles)**:
- Starts at ~0.32 (Top K=1)
- Rises sharply to ~0.52 (Top K=4)
- Plateaus at ~0.52 (Top K=5–8)
2. **Claude Accuracy (orange squares)**:
- Starts at ~0.3 (Top K=1)
- Increases gradually to ~0.45 (Top K=5)
- Remains flat at ~0.45 (Top K=6–8)
3. **GPT Number of Data (blue triangles)**:
- Begins at ~200 (Top K=1)
- Declines steadily to ~10 (Top K=7)
- Drops to ~5 (Top K=8)
4. **Claude Number of Data (orange diamonds)**:
- Starts at ~180 (Top K=1)
- Falls sharply to ~10 (Top K=5)
- Remains at ~5 (Top K=6–8)
### Key Observations
- **Accuracy Trends**:
- GPT Accuracy improves significantly with more retrieved knowledge, then stabilizes.
- Claude Accuracy increases modestly and plateaus earlier than GPT.
- **Data Point Trends**:
- Both systems show a strong inverse relationship between retrieved knowledge and data points.
- Claude’s data points drop more sharply than GPT’s after Top K=5.
### Interpretation
1. **Performance Insights**:
- GPT benefits more from additional retrieved knowledge, achieving higher accuracy gains compared to Claude.
- Claude’s accuracy stabilizes at ~0.45, suggesting diminishing returns beyond Top K=5.
- The sharp decline in data points for both systems implies that retrieving more knowledge items becomes increasingly resource-intensive or inefficient.
2. **Anomalies**:
- Claude’s data points drop to near-zero (5) by Top K=6, while GPT retains ~10 data points at Top K=8. This may indicate Claude’s retrieval process becomes less effective or exhaustive at higher K values.
3. **Practical Implications**:
- For applications prioritizing accuracy, GPT may be preferable when sufficient data is available.
- Claude’s efficiency (fewer data points) might make it suitable for resource-constrained scenarios, despite lower accuracy ceilings.
4. **Uncertainties**:
- Exact values for data points (e.g., GPT Accuracy at Top K=3) are approximate due to overlapping markers.
- The secondary y-axis scale (Number of Data) lacks gridlines, complicating precise interpolation.