# Technical Document: Analysis of RLHF and DPO Methodologies
## Diagram Overview
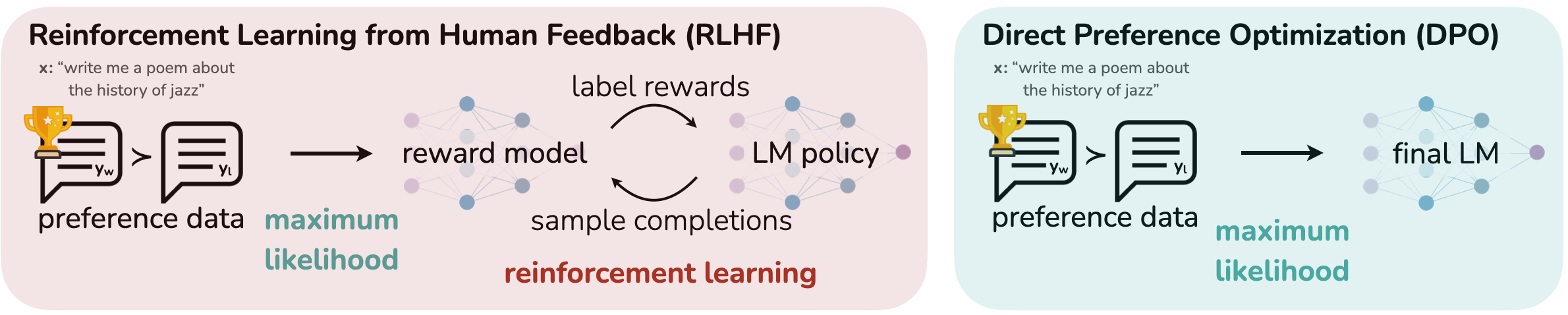
The image compares two machine learning methodologies for optimizing language models (LMs) using human feedback: **Reinforcement Learning from Human Feedback (RLHF)** and **Direct Preference Optimization (DPO)**. Both diagrams illustrate workflows starting with a user prompt and ending with a final LM, but differ in intermediate steps.
---
### **Left Diagram: Reinforcement Learning from Human Feedback (RLHF)**
#### Components and Flow:
1. **Input Prompt**
- Text: `"write me a poem about the history of jazz"`
- Visual: Speech bubble with trophy icon labeled `Y_w` (preferred output).
2. **Preference Data**
- Speech bubble labeled `Y_l` (less preferred output).
- Arrows indicate comparison between `Y_w` and `Y_l`.
3. **Reward Model**
- Neural network diagram with interconnected nodes (blue/purple colors).
- Purpose: Converts preference data into **label rewards**.
4. **LM Policy**
- Neural network diagram (similar structure to reward model).
- Receives label rewards and generates **sample completions**.
5. **Reinforcement Learning**
- Feedback loop between LM policy and reward model.
- Goal: Maximize **maximum likelihood**.
6. **Final LM**
- Output LM optimized via RLHF.
#### Key Textual Elements:
- **Labels**:
- `preference data`
- `maximum likelihood`
- `reinforcement learning`
- **Arrows**: Indicate data flow and iterative optimization.
---
### **Right Diagram: Direct Preference Optimization (DPO)**
#### Components and Flow:
1. **Input Prompt**
- Text: `"write me a poem about the history of jazz"`
- Visual: Speech bubble with trophy icon labeled `Y_w`.
2. **Preference Data**
- Speech bubble labeled `Y_l`.
- Arrows compare `Y_w` and `Y_l`.
3. **Final LM**
- Neural network diagram (simplified compared to RLHF).
- Directly optimized using preference data to achieve **maximum likelihood**.
#### Key Textual Elements:
- **Labels**:
- `preference data`
- `maximum likelihood`
- **Arrows**: Linear flow from preference data to final LM.
---
### **Comparison of RLHF and DPO**
| **Aspect** | **RLHF** | **DPO** |
|--------------------------|-------------------------------------------|------------------------------------------|
| **Intermediate Steps** | Reward model + LM policy + reinforcement learning | Direct optimization |
| **Complexity** | Multi-stage process | Simplified, single-stage process |
| **Optimization Goal** | Maximize likelihood via reinforcement | Maximize likelihood directly |
---
### **Visual Design Notes**
- **Color Coding**:
- RLHF: Pink background with blue/purple neural network nodes.
- DPO: Blue background with lighter blue neural network nodes.
- **Icons**: Trophy symbols denote preferred outputs (`Y_w`).
- **Text Consistency**: Both diagrams use identical input prompts and preference data labels.
---
### **Conclusion**
- **RLHF** employs a reward model and reinforcement learning to iteratively refine the LM.
- **DPO** bypasses intermediate steps, directly optimizing the LM using preference data.
- Both aim to maximize likelihood but differ in methodology complexity.