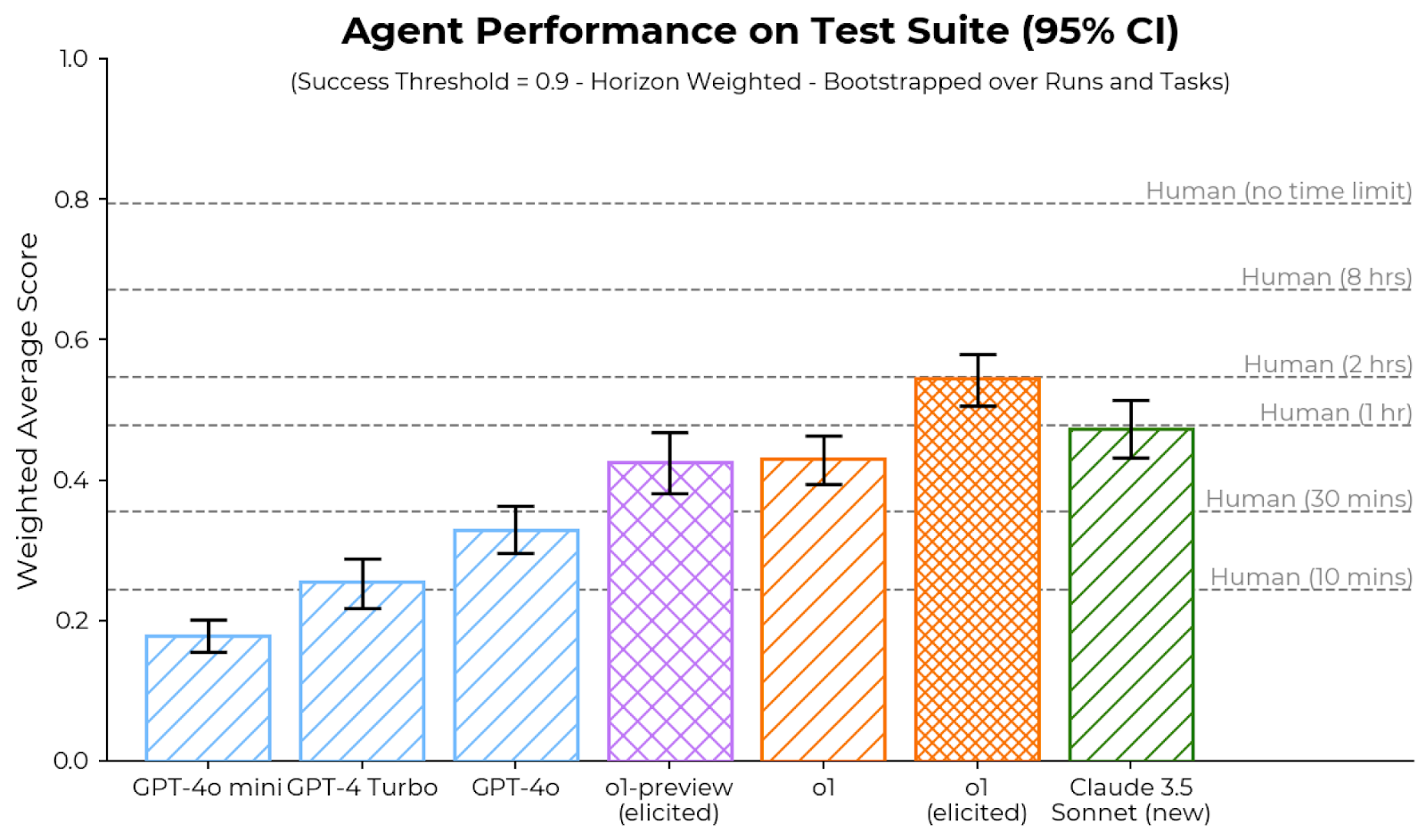
## Bar Chart: Agent Performance on Test Suite (95% CI)
### Overview
The chart compares the weighted average performance scores of various AI agents and human benchmarks on a test suite. Scores are presented with 95% confidence intervals (error bars) and normalized to a success threshold of 0.9. The x-axis categorizes agents by model type and human time constraints, while the y-axis represents performance scores (0–1.0). Human performance bars are positioned at the top, followed by AI models in descending order of capability.
### Components/Axes
- **X-Axis (Categories)**:
- Human (no time limit)
- Human (8 hrs)
- Human (2 hrs)
- Human (1 hr)
- Human (30 mins)
- Human (10 mins)
- GPT-4o mini
- GPT-4 Turbo
- GPT-4o
- o1-preview (elicited)
- o1 (elicited)
- Claude 3.5 Sonnet (new)
- **Y-Axis (Weighted Average Score)**:
- Scale: 0.0 to 1.0 in increments of 0.2
- Success threshold: Horizontal dashed line at 0.9
- **Legend**:
- **Colors/Patterns**:
- Human (no time limit): Solid gray
- Human (8 hrs): Solid orange
- Human (2 hrs): Solid orange
- Human (1 hr): Solid orange
- Human (30 mins): Solid orange
- Human (10 mins): Solid orange
- GPT-4o mini: Light blue (diagonal stripes)
- GPT-4 Turbo: Light blue (diagonal stripes)
- GPT-4o: Light blue (diagonal stripes)
- o1-preview (elicited): Purple (crosshatch)
- o1 (elicited): Orange (diagonal stripes)
- Claude 3.5 Sonnet (new): Green (diagonal stripes)
### Detailed Analysis
1. **Human Performance**:
- All human bars exceed 0.8, with "Human (no time limit)" at ~0.95 (highest).
- Scores decrease with shorter time limits:
- 8 hrs: ~0.85
- 2 hrs: ~0.82
- 1 hr: ~0.80
- 30 mins: ~0.78
- 10 mins: ~0.75
2. **AI Model Performance**:
- **Lowest**: GPT-4o mini (~0.18, error ±0.02)
- **Highest**: Claude 3.5 Sonnet (new) (~0.48, error ±0.03)
- Intermediate models:
- GPT-4 Turbo (~0.25, error ±0.03)
- GPT-4o (~0.32, error ±0.04)
- o1-preview (elicited) (~0.42, error ±0.04)
- o1 (elicited) (~0.43, error ±0.03)
3. **Error Bars**:
- Human scores have minimal variability (error bars <0.02).
- AI models show larger uncertainty, especially GPT-4o mini (±0.02) and GPT-4o (±0.04).
### Key Observations
- **Human Dominance**: All human performance scores exceed the 0.9 success threshold, while no AI model reaches it.
- **Time Constraints**: Human performance degrades with shorter time limits, but remains above 0.75 even at 10 minutes.
- **Model Variance**: Claude 3.5 Sonnet (new) outperforms other AI models by ~20–30%, with the smallest error margin.
- **Elicited vs. Non-Elicited**: "o1-preview (elicited)" and "o1 (elicited)" show slightly higher scores than non-elicited models, suggesting prompting improves performance.
### Interpretation
The data highlights a significant performance gap between AI agents and human benchmarks, even under time constraints. While Claude 3.5 Sonnet (new) demonstrates the strongest AI capability, it still falls short of human performance by ~50%. The success threshold of 0.9 remains unattained by all models, indicating substantial room for improvement in AI test suite performance. The error bars suggest that some models (e.g., GPT-4o) exhibit higher variability, potentially due to task complexity or evaluation methodology. The "elicited" variants of o1 models imply that structured prompting or task-specific guidance can marginally enhance AI performance, but this effect is limited compared to human adaptability.