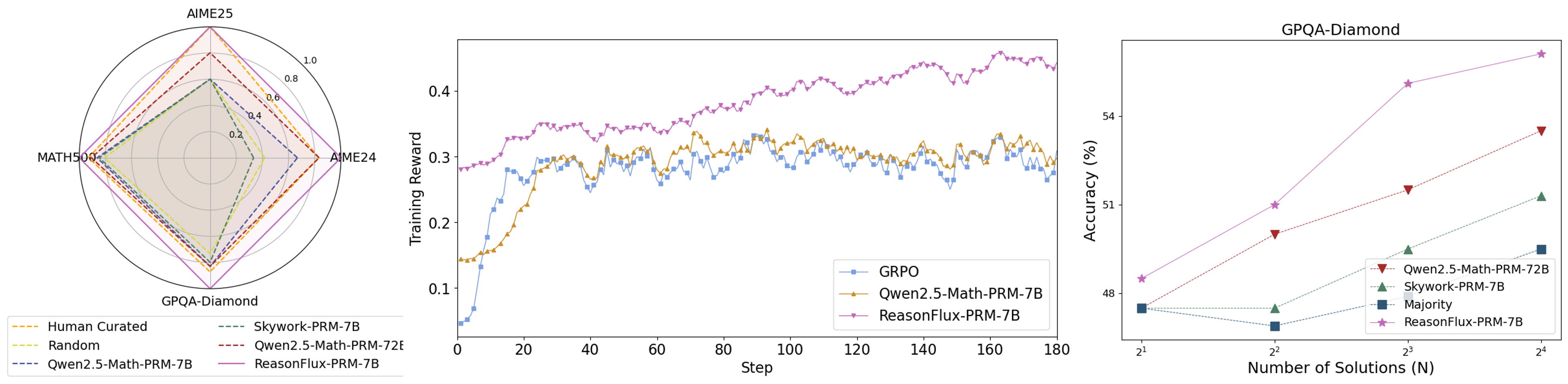
## Charts: Performance Comparison of Reasoning Agents
### Overview
The image presents three charts comparing the performance of different reasoning agents (GRPO, Owen2.5-Math-PRM-TB, Skywork-PRM-TB, ReasonFlux-PRM-TB, and Majority) across three datasets (AIME25, MATH50K, and GPQA-Diamond). The charts show performance in terms of radial plots for AIME25, a line graph of training reward over steps, and a line graph of accuracy versus the number of solutions.
### Components/Axes
* **Chart 1 (AIME25):** Radial plot with axes representing performance on AIME25. The radial scale ranges from 0 to 1.0. The legend is located at the bottom-left, listing the agents: "Human Curated" (dark blue), "Random" (light gray), "Skywork-PRM-TB" (orange), "Owen2.5-Math-PRM-TB" (yellow), "Owen2.5-Math-PRM-72E" (dashed yellow), and "ReasonFlux-PRM-TB" (purple).
* **Chart 2 (Training Reward):** Line graph with "Step" on the x-axis (ranging from 0 to 180) and "Training Reward" on the y-axis (ranging from 0.1 to 0.5). The legend is located at the top-right, listing the agents: "GRPO" (blue), "Owen2.5-Math-PRM-TB" (orange), and "ReasonFlux-PRM-TB" (purple).
* **Chart 3 (GPQA-Diamond):** Line graph with "Number of Solutions (N)" on the x-axis (ranging from 2<sup>1</sup> to 2<sup>5</sup>) and "Accuracy (%)" on the y-axis (ranging from 48% to 54%). The legend is located at the top-right, listing the agents: "Owen2.5-Math-PRM-TB" (orange), "Skywork-PRM-TB" (green), "Majority" (black), and "ReasonFlux-PRM-TB" (purple).
### Detailed Analysis or Content Details
**Chart 1 (AIME25):**
* **Human Curated:** Shows a relatively consistent performance across the AIME25 dataset, with values around 0.8-0.9.
* **Random:** Exhibits very low performance, consistently below 0.2.
* **Skywork-PRM-TB:** Performance fluctuates, with values ranging from approximately 0.3 to 0.7.
* **Owen2.5-Math-PRM-TB:** Performance is moderate, with values ranging from approximately 0.4 to 0.8.
* **Owen2.5-Math-PRM-72E:** Similar to Owen2.5-Math-PRM-TB, with values ranging from approximately 0.4 to 0.8.
* **ReasonFlux-PRM-TB:** Shows the highest performance, consistently above 0.7 and reaching close to 1.0.
**Chart 2 (Training Reward):**
* **GRPO (Blue):** The line fluctuates around 0.3, with some oscillations. At step 180, the reward is approximately 0.32.
* **Owen2.5-Math-PRM-TB (Orange):** The line fluctuates around 0.35, with more pronounced oscillations than GRPO. At step 180, the reward is approximately 0.38.
* **ReasonFlux-PRM-TB (Purple):** The line shows a generally increasing trend, starting around 0.3 and reaching approximately 0.45 at step 180.
**Chart 3 (GPQA-Diamond):**
* **Owen2.5-Math-PRM-TB (Orange):** Starts at approximately 48% accuracy at N=2<sup>1</sup> and increases to approximately 52% at N=2<sup>5</sup>.
* **Skywork-PRM-TB (Green):** Starts at approximately 49% accuracy at N=2<sup>1</sup> and increases to approximately 53% at N=2<sup>5</sup>.
* **Majority (Black):** Starts at approximately 48% accuracy at N=2<sup>1</sup> and remains relatively flat, reaching approximately 49% at N=2<sup>5</sup>.
* **ReasonFlux-PRM-TB (Purple):** Starts at approximately 48% accuracy at N=2<sup>1</sup> and increases sharply to approximately 54% at N=2<sup>5</sup>.
### Key Observations
* ReasonFlux-PRM-TB consistently outperforms other agents across all three datasets.
* The training reward for ReasonFlux-PRM-TB shows a clear upward trend, suggesting continued learning.
* Accuracy on GPQA-Diamond increases with the number of solutions for most agents, but ReasonFlux-PRM-TB shows the most significant improvement.
* The "Majority" agent shows minimal improvement in accuracy with increasing solutions.
### Interpretation
The data suggests that ReasonFlux-PRM-TB is the most effective reasoning agent among those tested, demonstrating superior performance on AIME25, higher training rewards, and greater accuracy gains on GPQA-Diamond as the number of solutions increases. The radial plot for AIME25 visually confirms this, with ReasonFlux-PRM-TB extending furthest towards the outer edge of the plot, indicating higher performance. The increasing training reward for ReasonFlux-PRM-TB suggests that it is capable of continued learning and improvement. The relatively flat performance of the "Majority" agent on GPQA-Diamond indicates that simply aggregating multiple solutions does not necessarily lead to improved accuracy, highlighting the importance of sophisticated reasoning capabilities. The differences in performance between the agents likely stem from variations in their underlying architectures and training methodologies. The fact that Owen2.5-Math-PRM-72E and Owen2.5-Math-PRM-TB perform similarly suggests that the 72E parameter does not significantly impact performance in this context.