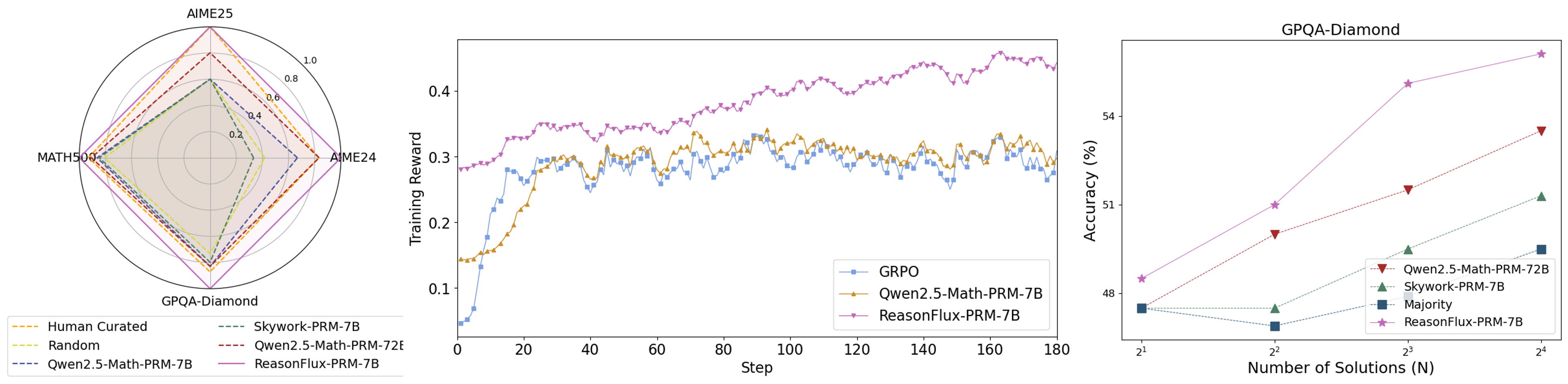
## Composite Visualization: Multi-Model Performance Analysis (Radar, Training Reward, Accuracy)
### Overview
The image contains three distinct visualizations analyzing model performance across tasks, training dynamics, and solution scaling: a **radar chart** (left), a **line graph** (middle), and a **scatter plot** (right).
### 1. Left: Radar Chart (Multi-Task Performance)
- **Axes & Scale**: Four radial axes: *AIME25* (top), *MATH500* (left), *AIME24* (right), *GPQA-Diamond* (bottom). Radial scale: 0.0–1.0 (markers at 0.2, 0.4, 0.6, 0.8, 1.0).
- **Legend (Bottom)**: Six models (line styles/colors):
- Human Curated (orange dashed)
- Random (yellow dashed)
- Qwen2.5-Math-PRM-7B (blue dashed)
- Skywork-PRM-7B (green dashed)
- Qwen2.5-Math-PRM-72B (red dashed)
- ReasonFlux-PRM-7B (purple solid)
- **Trends**:
- *ReasonFlux-PRM-7B* (purple) dominates across all axes (highest values on AIME25, GPQA-Diamond, etc.).
- *Human Curated* (orange) and *Random* (yellow) show moderate performance, while *Qwen2.5-Math-PRM-7B* (blue) and *Skywork-PRM-7B* (green) have lower scores.
### 2. Middle: Line Graph (Training Reward vs. Step)
- **Axes**:
- Y-axis: *Training Reward* (0.0–0.4).
- X-axis: *Step* (0–180).
- **Legend (Bottom-Right)**: Three models:
- GRPO (blue, square markers)
- Qwen2.5-Math-PRM-7B (orange, triangle markers)
- ReasonFlux-PRM-7B (purple, star markers)
- **Trends**:
- *GRPO* (blue): Starts low (~0.05), rises to ~0.3 by step 20, then fluctuates (0.25–0.3).
- *Qwen2.5-Math-PRM-7B* (orange): Starts ~0.15, rises to ~0.3, then fluctuates (similar to GRPO but slightly higher).
- *ReasonFlux-PRM-7B* (purple): Starts ~0.28, rises steadily to ~0.45 by step 180 (clear upward trend, outperforming others).
### 3. Right: Scatter Plot (Accuracy vs. Number of Solutions, GPQA-Diamond)
- **Title**: *GPQA-Diamond*
- **Axes**:
- Y-axis: *Accuracy (%)* (48–54).
- X-axis: *Number of Solutions (N)* (2¹, 2², 2³, 2⁴ = 2, 4, 8, 16).
- **Legend (Bottom-Right)**: Four models:
- Qwen2.5-Math-PRM-72B (red triangle)
- Skywork-PRM-7B (green triangle)
- Majority (blue square)
- ReasonFlux-PRM-7B (purple star)
- **Data Points (Approximate)**:
- *ReasonFlux-PRM-7B* (purple): N=2¹ (~48.5%), N=2² (~51%), N=2³ (~54%), N=2⁴ (~55%) (highest accuracy).
- *Qwen2.5-Math-PRM-72B* (red): N=2¹ (~48%), N=2² (~50%), N=2³ (~52%), N=2⁴ (~54%).
- *Skywork-PRM-7B* (green): N=2¹ (~48%), N=2² (~49%), N=2³ (~51%), N=2⁴ (~52%).
- *Majority* (blue): N=2¹ (~48%), N=2² (~47.5%), N=2³ (~48.5%), N=2⁴ (~49%) (lowest, with a dip at N=2²).
### Key Observations
- **Radar Chart**: *ReasonFlux-PRM-7B* outperforms all models across multi-task benchmarks (AIME25, MATH500, AIME24, GPQA-Diamond).
- **Training Reward**: *ReasonFlux-PRM-7B* shows a consistent upward trend in training reward, while GRPO and Qwen2.5-Math-PRM-7B plateau.
- **Accuracy Scaling**: *ReasonFlux-PRM-7B* achieves the highest accuracy on GPQA-Diamond, with accuracy increasing with the number of solutions (N). *Majority* (baseline) performs poorly, especially at N=2².
### Interpretation
- **Multi-Task Strength**: *ReasonFlux-PRM-7B* demonstrates superior performance across diverse tasks (AIME, MATH, GPQA), suggesting robust generalization.
- **Training Efficiency**: The upward trend in training reward for *ReasonFlux-PRM-7B* indicates effective learning over steps, outpacing GRPO and Qwen2.5-Math-PRM-7B.
- **Solution Scaling**: For GPQA-Diamond, increasing the number of solutions (N) improves accuracy for all models, but *ReasonFlux-PRM-7B* benefits most, highlighting its ability to leverage more solutions for better performance.
This composite visualization collectively illustrates *ReasonFlux-PRM-7B*’s dominance in multi-task performance, training dynamics, and solution scaling, outperforming baselines (GRPO, Qwen2.5-Math-PRM-7B, Majority) across all metrics.