TECHNICAL ASSET FINGERPRINT
b06c087935b800c77daa437f
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
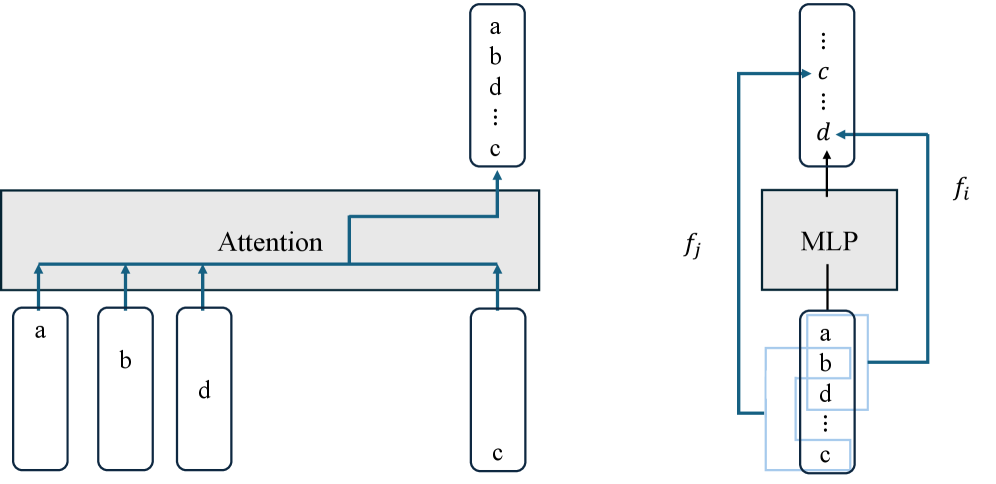
## Diagram: Attention and MLP Component Flow
### Overview
The image is a technical diagram illustrating two fundamental components of a neural network architecture, likely a transformer or similar model. It is divided into two distinct sections: a left panel depicting an **Attention** mechanism and a right panel depicting a **Multi-Layer Perceptron (MLP)** block. The diagram uses a consistent visual language of gray blocks, blue arrows, and labeled rectangular nodes to represent data flow and transformations.
### Components/Axes
The diagram contains no traditional chart axes. Its components are:
**Left Panel (Attention Mechanism):**
* **Central Block:** A wide, horizontal gray rectangle labeled **"Attention"** in its center.
* **Input Nodes (Bottom):** Four vertically oriented, rounded rectangles positioned below the Attention block.
* Three are grouped on the left, labeled **"a"**, **"b"**, and **"d"** from left to right.
* One is isolated on the right, labeled **"c"**.
* **Output Node (Top):** A single, vertically oriented, rounded rectangle positioned above the Attention block, slightly to the right of center. It contains a vertical list of labels: **"a"**, **"b"**, **"d"**, **"..."** (ellipsis), and **"c"**.
* **Data Flow (Arrows):**
* Blue arrows point upward from each of the four input nodes ("a", "b", "d", "c") into the bottom of the Attention block.
* A blue arrow originates from the top of the Attention block and points to the output node.
* A specific blue arrow path is highlighted: it originates from the input node **"c"**, travels horizontally left within the Attention block, then turns upward to connect to the **"c"** in the output node's list.
**Right Panel (MLP Block):**
* **Central Block:** A square gray block labeled **"MLP"** in its center.
* **Input Node (Bottom):** A vertically oriented, rounded rectangle positioned below the MLP block. It contains a vertical list of labels: **"a"**, **"b"**, **"d"**, **"..."** (ellipsis), and **"c"**. This list is visually identical to the output node from the left panel.
* **Output Node (Top):** A vertically oriented, rounded rectangle positioned above the MLP block. It contains a vertical list of labels: **"..."** (ellipsis) at the top, followed by **"c"**, another **"..."** (ellipsis), and **"d"** at the bottom.
* **Data Flow (Arrows & Functions):**
* A blue arrow points upward from the center of the bottom input node into the MLP block.
* A blue arrow points upward from the top of the MLP block into the center of the top output node.
* **Bypass/Skip Connections:** Two curved blue arrows create direct connections from the bottom input node to the top output node, bypassing the MLP.
* One arrow originates from the label **"a"** in the bottom node and points to the label **"c"** in the top node. This connection is labeled **`f_i`**.
* Another arrow originates from the label **"b"** in the bottom node and points to the label **"d"** in the top node. This connection is labeled **`f_j`**.
* A faint, light-blue rectangular outline surrounds the bottom input node, possibly indicating it is a single tensor or grouped data structure.
### Detailed Analysis
The diagram explicitly maps the transformation of a set of elements {a, b, c, d}.
1. **Attention Stage (Left):**
* **Input:** Four separate elements: `a`, `b`, `d`, `c`.
* **Process:** The Attention mechanism processes these inputs. The highlighted path for element `c` suggests it is being attended to or re-weighted.
* **Output:** The elements are reordered into a sequence: `a`, `b`, `d`, `...`, `c`. The ellipsis (`...`) implies there may be additional, unspecified elements in the sequence between `d` and `c`. The output is a single, ordered representation.
2. **MLP Stage (Right):**
* **Input:** The ordered sequence from the Attention output: `[a, b, d, ..., c]`.
* **Process:** This sequence is processed in two parallel ways:
* **Through the MLP:** The entire sequence is passed through the MLP block for nonlinear transformation.
* **Via Direct Mapping:** Specific elements are mapped directly to the output via functions `f_i` and `f_j`. Element `a` is transformed by `f_i` to become `c` in the output. Element `b` is transformed by `f_j` to become `d` in the output.
* **Output:** A new sequence: `[..., c, ..., d]`. The ellipses indicate a sequence of unspecified length and content, with the known transformed elements `c` and `d` placed at specific positions.
### Key Observations
* **Consistent Element Set:** The core elements `a`, `b`, `c`, and `d` are tracked through both stages.
* **Role of Ellipses (`...`):** The ellipses are critical. They indicate that the sequences contain more elements than are explicitly labeled, making this a generalized diagram rather than a specific example with four items.
* **Dual-Path Processing in MLP:** The MLP block does not solely process the input sequence. It works in conjunction with direct, element-wise functional mappings (`f_i`, `f_j`), suggesting a hybrid transformation.
* **Spatial Grounding:** The legend/labels (`f_i`, `f_j`) are placed directly next to their corresponding bypass arrows. The input to the MLP is spatially aligned with the output from the Attention block, confirming data flow between the two components.
### Interpretation
This diagram illustrates a common pattern in advanced neural network architectures, particularly transformers.
* **Attention's Role:** The left panel shows the **Attention mechanism's core function: reordering and contextualizing input elements.** It takes a set of tokens (a, b, d, c) and produces an ordered sequence where the position of `c` is specifically highlighted, likely indicating it has been given contextual importance relative to the others. The output is a context-aware representation.
* **MLP's Role:** The right panel shows the **MLP's role in feature transformation and refinement.** It takes the context-aware sequence and applies two types of operations:
1. A **global, nonlinear transformation** via the MLP block itself, which likely mixes information across all positions.
2. **Specific, element-wise transformations** (`f_i`, `f_j`) that map certain input features directly to different output features (e.g., `a -> c`, `b -> d`). This could represent operations like position-wise feed-forward networks or specific feature projections.
* **Architectural Insight:** The diagram emphasizes that the output of one major component (Attention) becomes the direct input to the next (MLP), forming a pipeline. The bypass connections (`f_i`, `f_j`) suggest that not all information is processed through the same pathway; some transformations are direct and specific, while others are global and contextual. This is a visual representation of how information flows and is transformed in a layer of a deep learning model, balancing contextual mixing with targeted feature update.
DECODING INTELLIGENCE...