## Diagram: Multi-Agent Reinforcement Learning System
### Overview
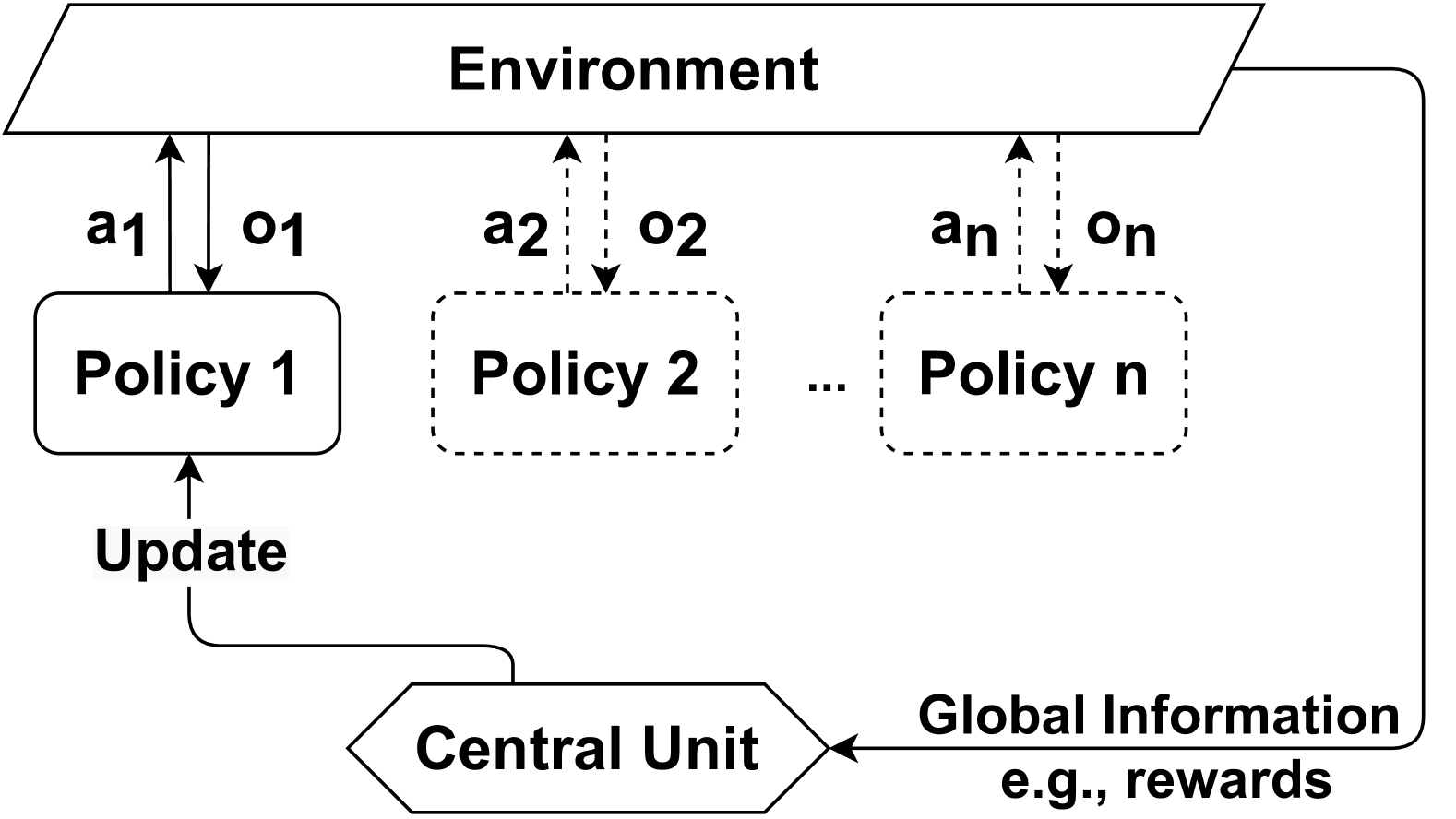
The image is a diagram illustrating a multi-agent reinforcement learning system. It depicts multiple policies interacting with an environment, with a central unit coordinating updates based on global information.
### Components/Axes
* **Environment:** A trapezoidal shape at the top, representing the external environment.
* **Policies:** Three policy blocks are shown: "Policy 1" (solid outline), "Policy 2" (dashed outline), and "Policy n" (dashed outline). The "..." between Policy 2 and Policy n indicates that there are potentially more policies in the system.
* **Central Unit:** A diamond shape at the bottom, labeled "Central Unit."
* **Actions:** Arrows labeled "a1", "a2", and "an" point upwards from each policy to the environment, representing actions taken by the policies.
* **Observations:** Dashed arrows labeled "o1", "o2", and "on" point downwards from the environment to each policy, representing observations received by the policies.
* **Update:** An arrow labeled "Update" points upwards from the Central Unit to Policy 1.
* **Global Information:** An arrow points from the Central Unit to the right, labeled "Global Information e.g., rewards".
* **Feedback Loop:** An arrow points from the right side of the Environment back to the Central Unit.
### Detailed Analysis
* **Environment Interaction:** Each policy interacts with the environment by taking actions (a1, a2, an) and receiving observations (o1, o2, on).
* **Central Coordination:** The Central Unit receives global information (e.g., rewards) from the environment.
* **Policy Update:** The Central Unit updates Policy 1. The diagram does not explicitly show how other policies are updated, but it implies a similar mechanism.
* **Policy Representation:** Policy 1 is represented with a solid outline, while Policy 2 and Policy n are represented with dashed outlines. This might indicate a difference in their implementation or status (e.g., Policy 1 is active, while others are being trained).
### Key Observations
* The system involves multiple policies interacting with a shared environment.
* A central unit coordinates the policies based on global information.
* The diagram highlights the flow of information between the environment, policies, and the central unit.
### Interpretation
The diagram illustrates a common architecture for multi-agent reinforcement learning. The policies act as individual agents, learning to optimize their behavior within the environment. The central unit plays a crucial role in coordinating the agents, potentially by sharing information, providing rewards, or updating the policies directly. The dashed lines for Policy 2 and Policy n suggest that the system is scalable and can accommodate a variable number of agents. The "Update" arrow specifically targeting Policy 1 might indicate a centralized update mechanism, or it could be a simplified representation of a more complex update process that applies to all policies. The global information, such as rewards, is essential for guiding the learning process of the agents.