\n
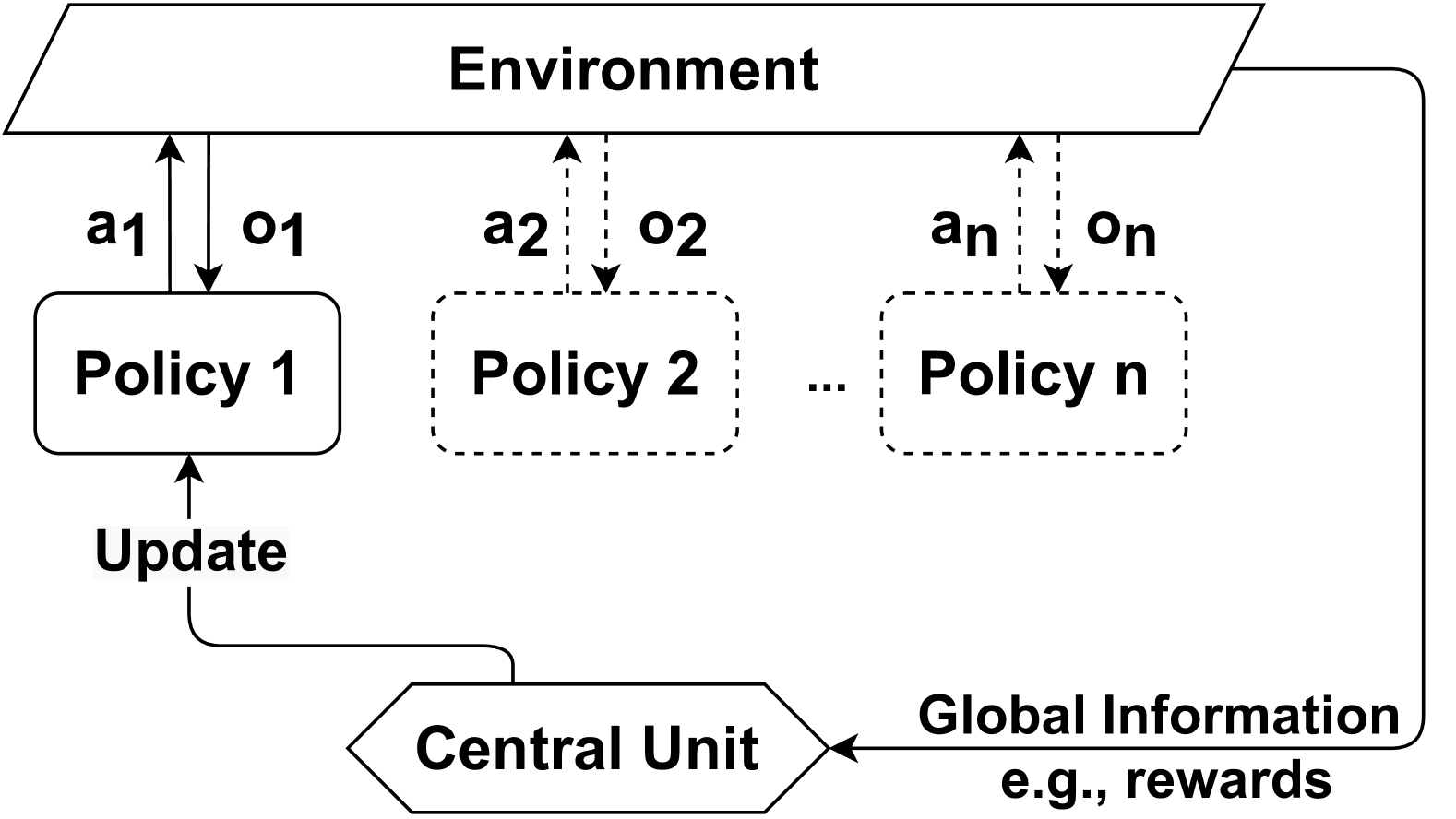
## Diagram: Multi-Agent Reinforcement Learning System
### Overview
The image depicts a diagram illustrating a multi-agent reinforcement learning system within an environment. It shows multiple policies interacting with the environment and a central unit coordinating information exchange. The diagram emphasizes the flow of actions, observations, and global information between agents and the central unit.
### Components/Axes
The diagram consists of the following components:
* **Environment:** A large, grey rectangle at the top, labeled "Environment".
* **Policies:** Multiple rectangular blocks labeled "Policy 1", "Policy 2", ..., "Policy n". Policy 2 through n are dashed.
* **Actions:** Labels "a1", "a2", ..., "an" representing actions taken by each policy.
* **Observations:** Labels "o1", "o2", ..., "on" representing observations received by each policy.
* **Central Unit:** A hexagonal shape at the bottom, labeled "Central Unit".
* **Update:** A curved arrow pointing from Policy 1 to itself, labeled "Update".
* **Global Information:** Text "Global Information e.g., rewards" pointing towards the Central Unit.
* **Arrows:** Various arrows indicating the flow of information between components.
### Detailed Analysis or Content Details
The diagram illustrates the following interactions:
1. **Policy 1:** Receives an observation "o1" from the Environment, takes action "a1", and sends it back to the Environment. It also receives an "Update" signal from itself, indicating a learning or adjustment process.
2. **Policy 2 to Policy n:** Each policy receives an observation "o2" to "on" from the Environment, takes action "a2" to "an", and sends it back to the Environment. These policies are represented with dashed borders, suggesting they may be similar or representative of a larger set.
3. **Environment:** Receives actions "a1" to "an" from all policies.
4. **Central Unit:** Receives "Global Information" (e.g., rewards) and sends information to all policies. The arrows connecting the Central Unit to each policy are solid lines.
5. **Information Flow:** The arrows indicate a cyclical flow of information. Policies interact with the environment, the environment provides observations, and the central unit coordinates information exchange.
### Key Observations
* The diagram highlights a decentralized control structure where multiple policies operate within a shared environment.
* The "Central Unit" acts as a coordinator, collecting global information and potentially distributing it to the policies.
* The dashed borders around Policies 2 through n suggest a scalable architecture where the number of policies can be increased.
* The "Update" signal for Policy 1 indicates a self-learning or iterative improvement process.
### Interpretation
This diagram represents a multi-agent reinforcement learning (MARL) system. The agents (Policies) learn to interact with the environment to maximize a reward signal. The central unit likely plays a role in aggregating information from all agents, potentially for centralized learning or coordination. The dashed lines for Policies 2-n suggest a generalizable architecture applicable to a variable number of agents. The "Update" signal for Policy 1 indicates that each policy is independently learning and improving its strategy based on its experiences. The system is designed to handle complex environments where multiple agents need to cooperate or compete to achieve a common goal. The inclusion of "e.g., rewards" suggests that the global information could include other relevant data points for the agents to learn from.