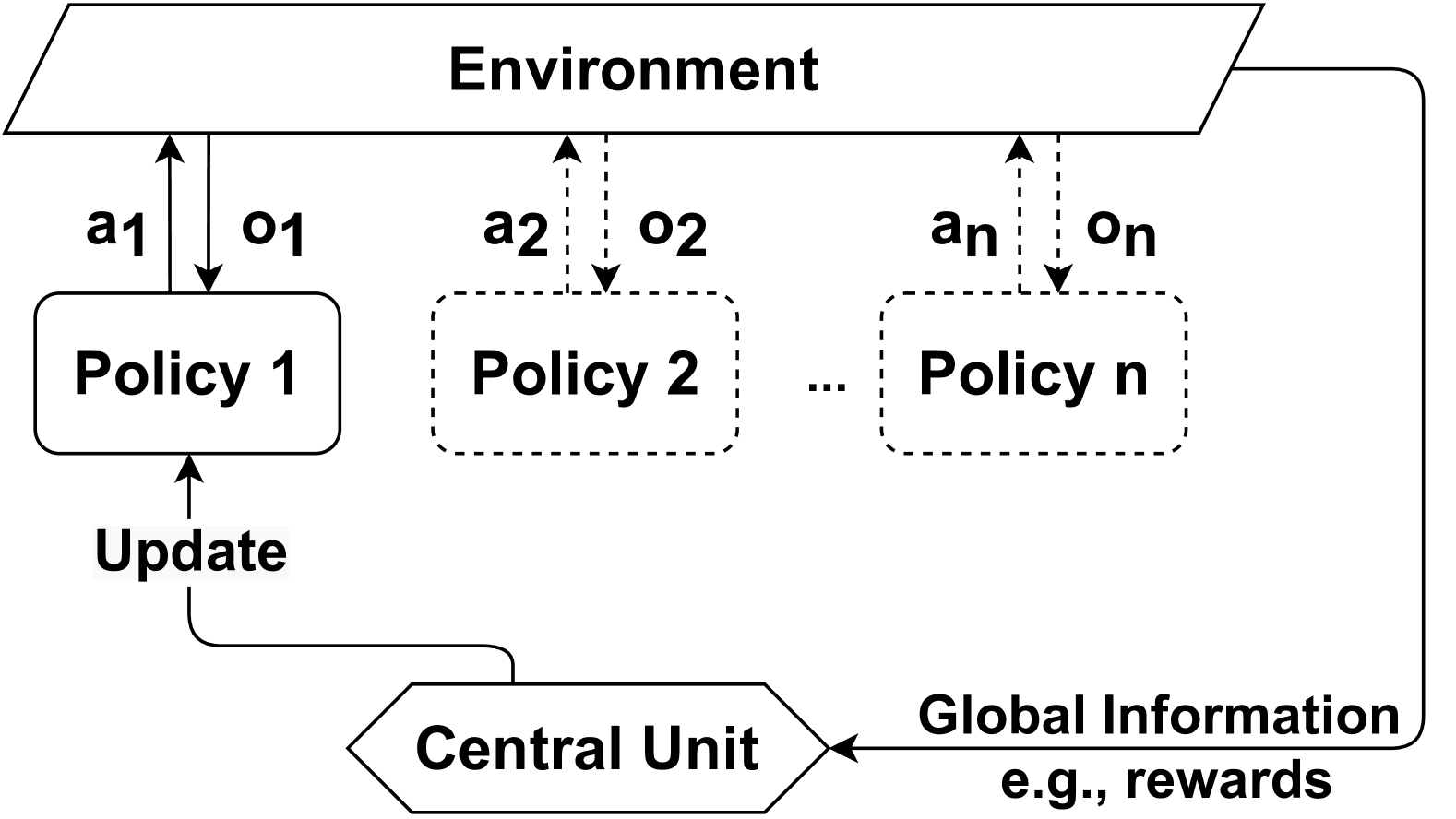
## Diagram: Multi-Policy System Architecture
### Overview
The diagram illustrates a multi-policy system interacting with an environment. It shows a hierarchical structure where multiple policies (Policy 1 to Policy n) receive actions from an environment, generate observations, and are updated via a central unit that processes global information (e.g., rewards).
### Components/Axes
1. **Environment**: A rectangular block at the top, labeled "Environment," acting as the source of actions (`a1`, `a2`, ..., `an`) and observations (`o1`, `o2`, ..., `on`).
2. **Policies**:
- **Policy 1**: A solid rectangle with a feedback loop labeled "Update," indicating iterative refinement.
- **Policy 2 to Policy n**: Dashed rectangles, suggesting auxiliary or secondary policies.
3. **Central Unit**: A hexagonal block at the bottom, labeled "Central Unit," which receives "Global Information" (e.g., rewards) and distributes updates to Policy 1.
4. **Arrows**:
- Solid arrows from the Environment to Policies (actions).
- Dashed arrows from Policies to the Environment (observations).
- A feedback loop from the Central Unit to Policy 1 (updates).
### Detailed Analysis
- **Environment**:
- Sends actions (`a1`, `a2`, ..., `an`) to all policies.
- Receives observations (`o1`, `o2`, ..., `on`) from policies.
- **Policies**:
- **Policy 1**: Explicitly connected to the Central Unit via an "Update" arrow, implying it is the primary policy refined by global feedback.
- **Policy 2 to Policy n**: Dashed lines suggest they are part of the system but not directly updated by the Central Unit.
- **Central Unit**:
- Aggregates "Global Information" (e.g., rewards) and sends updates to Policy 1.
- No direct connection to Policies 2–n, indicating a hierarchical prioritization.
### Key Observations
1. **Hierarchical Structure**: Policy 1 is central to the update mechanism, while other policies operate in parallel but lack direct feedback.
2. **Dashed vs. Solid Lines**: Dashed lines for Policies 2–n may indicate they are secondary or exploratory, while Policy 1 is the primary focus.
3. **Feedback Loop**: The "Update" arrow creates a closed-loop system for Policy 1, enabling continuous improvement.
### Interpretation
This diagram represents a **multi-agent reinforcement learning (MARL)** or **distributed policy optimization** framework. The Environment acts as the external world, while Policies 1–n represent individual agents or strategies. The Central Unit likely coordinates learning by aggregating global rewards and refining Policy 1, which then influences the Environment. Policies 2–n may serve as exploratory or backup strategies, with their dashed connections suggesting they are not part of the core update cycle.
The system emphasizes **centralized learning** (via the Central Unit) while allowing decentralized execution (via multiple policies). The absence of direct feedback to Policies 2–n implies they may not contribute to the global update process, potentially limiting their role to auxiliary tasks.
**Notable Anomalies**:
- Policies 2–n lack explicit connections to the Central Unit, raising questions about their purpose.
- The "Update" label on Policy 1’s feedback loop is vague; it could imply gradient descent, reward-based tuning, or other mechanisms.