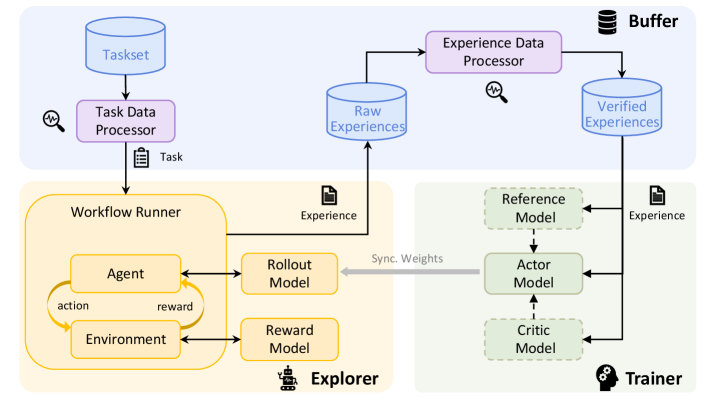
# Technical Document Extraction: Reinforcement Learning System Architecture
This document provides a comprehensive extraction and analysis of the provided architectural diagram, which illustrates a Reinforcement Learning (RL) pipeline consisting of three primary functional regions: **Buffer**, **Explorer**, and **Trainer**.
---
## 1. Component Isolation (Spatial Segmentation)
The diagram is divided into three color-coded regions:
* **Top Region (Blue Background):** The **Buffer** system, responsible for task management and data processing.
* **Bottom-Left Region (Yellow Background):** The **Explorer**, responsible for environment interaction and data generation.
* **Bottom-Right Region (Green Background):** The **Trainer**, responsible for model optimization and weight synchronization.
---
## 2. Detailed Component Extraction
### A. Buffer Region (Top)
* **Taskset (Database Icon):** The initial source of tasks.
* **Task Data Processor (Purple Box):** Processes data from the Taskset. Accompanied by a magnifying glass icon (indicating monitoring/inspection).
* **Raw Experiences (Database Icon):** Stores data generated by the Explorer.
* **Experience Data Processor (Purple Box):** Processes raw experiences. Accompanied by a magnifying glass icon.
* **Verified Experiences (Database Icon):** Stores the output of the Experience Data Processor, ready for training.
### B. Explorer Region (Bottom-Left)
* **Workflow Runner (Large Yellow Container):**
* **Agent (Yellow Box):** Sends an "action" to the Environment.
* **Environment (Yellow Box):** Sends a "reward" back to the Agent.
* **Rollout Model (Yellow Box):** Interfaces with the Agent.
* **Reward Model (Yellow Box):** Interfaces with the Environment.
* **Output:** Generates "Experience" (indicated by a document icon) which is sent to the **Raw Experiences** database.
### C. Trainer Region (Bottom-Right)
* **Reference Model (Green Dashed Box):** Used as a baseline for training.
* **Actor Model (Green Solid Box):** The primary model being trained.
* **Critic Model (Green Dashed Box):** Evaluates the actions of the Actor.
* **Input:** Receives "Experience" (indicated by a document icon) from the **Verified Experiences** database.
---
## 3. Process Flow and Logic
The system operates in a continuous loop characterized by the following data movements:
1. **Task Initialization:**
* `Taskset` $\rightarrow$ `Task Data Processor` $\rightarrow$ `Workflow Runner`.
* The transition is labeled with a clipboard icon and the text **"Task"**.
2. **Experience Generation (The Explorer Loop):**
* Inside the `Workflow Runner`, the `Agent` and `Environment` interact via an **action/reward** cycle.
* The `Rollout Model` and `Reward Model` support this interaction.
* The resulting data is labeled **"Experience"** and sent to the `Raw Experiences` database in the Buffer.
3. **Data Refinement:**
* `Raw Experiences` $\rightarrow$ `Experience Data Processor` $\rightarrow$ `Verified Experiences`.
* This stage ensures data quality before it reaches the training phase.
4. **Model Training (The Trainer):**
* `Verified Experiences` are fed into the `Reference Model`, `Actor Model`, and `Critic Model`.
* The `Actor Model` is the central component, flanked by the `Reference` and `Critic` models (indicated by vertical dashed arrows).
5. **Weight Synchronization (The Feedback Loop):**
* A thick grey arrow labeled **"Sync. Weights"** points from the `Actor Model` (Trainer) back to the `Rollout Model` (Explorer).
* This represents the deployment of the trained model back into the exploration phase to improve future data collection.
---
## 4. Textual Transcription
| Category | Transcribed Text |
| :--- | :--- |
| **Headers/Regions** | Buffer, Explorer, Trainer |
| **Data Stores** | Taskset, Raw Experiences, Verified Experiences |
| **Processors** | Task Data Processor, Experience Data Processor |
| **Explorer Components** | Workflow Runner, Agent, Environment, action, reward, Rollout Model, Reward Model |
| **Trainer Components** | Reference Model, Actor Model, Critic Model |
| **Data Labels** | Task, Experience, Experience, Sync. Weights |
---
## 5. Summary of Facts
* **Language:** English (100%).
* **System Type:** Distributed Reinforcement Learning Architecture.
* **Key Feature:** Decoupled data collection (Explorer) and model optimization (Trainer) mediated by a processing buffer.
* **Monitoring:** The presence of magnifying glass icons suggests that both Task and Experience processing stages are subject to automated or manual validation/monitoring.