\n
## Diagram: Reinforcement Learning Workflow
### Overview
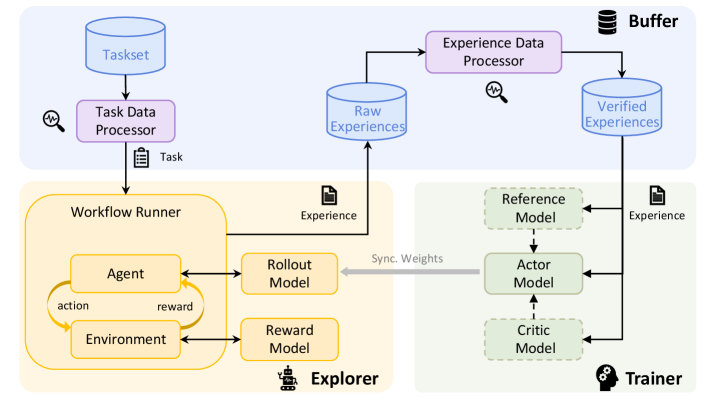
This diagram illustrates a reinforcement learning workflow, depicting the interaction between an agent, environment, and various processing components. The workflow is segmented into three main areas: a Task Processing section (top), an Explorer section (center-left), and a Trainer section (center-right). Data flow is indicated by arrows, and key components are represented as labeled boxes.
### Components/Axes
The diagram contains the following components:
* **Taskset:** A database of tasks.
* **Task Data Processor:** Processes the taskset and outputs a "Task".
* **Workflow Runner:** Contains the "Agent" and "Environment" and manages the interaction between them.
* **Agent:** Takes "action" and receives a "reward" from the environment.
* **Environment:** Provides feedback (reward) to the agent based on its actions.
* **Rollout Model:** Part of the Explorer, receives "Experience" from the Workflow Runner.
* **Reward Model:** Part of the Explorer, receives "Experience" from the Workflow Runner.
* **Explorer:** Contains the Rollout and Reward Models.
* **Experience Data Processor:** Processes "Raw Experiences" and outputs "Verified Experiences".
* **Raw Experiences:** A database of raw experiences.
* **Verified Experiences:** A database of verified experiences.
* **Reference Model:** Part of the Trainer, receives "Experience".
* **Actor Model:** Part of the Trainer, receives "Experience" from the Reference Model.
* **Critic Model:** Part of the Trainer, receives input from the Actor Model.
* **Trainer:** Contains the Reference, Actor, and Critic Models.
* **Buffer:** Stores verified experiences.
* **Sync. Weights:** Indicates synchronization of weights between models.
### Detailed Analysis or Content Details
The diagram shows a cyclical flow within the Workflow Runner: the Agent takes an action, the Environment provides a reward, and this cycle repeats. The Explorer receives "Experience" from the Workflow Runner. The Experience Data Processor transforms "Raw Experiences" into "Verified Experiences", which are stored in a "Buffer". The Trainer utilizes the "Verified Experiences" to update the Reference, Actor, and Critic Models. The "Sync. Weights" arrow indicates that the weights of the models are synchronized.
### Key Observations
The diagram highlights the separation of concerns in a reinforcement learning system: task generation, agent interaction, experience processing, and model training. The cyclical nature of the agent-environment interaction is clearly depicted. The flow of "Experience" is central to the entire process, being passed from the Workflow Runner to the Explorer, then to the Experience Data Processor, and finally to the Trainer.
### Interpretation
This diagram represents a common architecture for reinforcement learning algorithms, particularly those employing techniques like experience replay and actor-critic methods. The "Taskset" and "Task Data Processor" suggest a system capable of handling multiple tasks or a dynamic task environment. The separation of the "Explorer" and "Trainer" components is indicative of an off-policy learning approach, where the data used for training is not necessarily generated by the current policy. The "Reference Model" likely serves as a target or baseline for the Actor and Critic models, facilitating stable learning. The "Buffer" is a crucial component for experience replay, allowing the agent to learn from past experiences and break correlations in the data. The synchronization of weights suggests a mechanism for periodically updating the models in the Explorer with the latest knowledge from the Trainer. The overall workflow demonstrates a sophisticated system for learning optimal policies through trial and error, leveraging experience replay and model-based techniques.