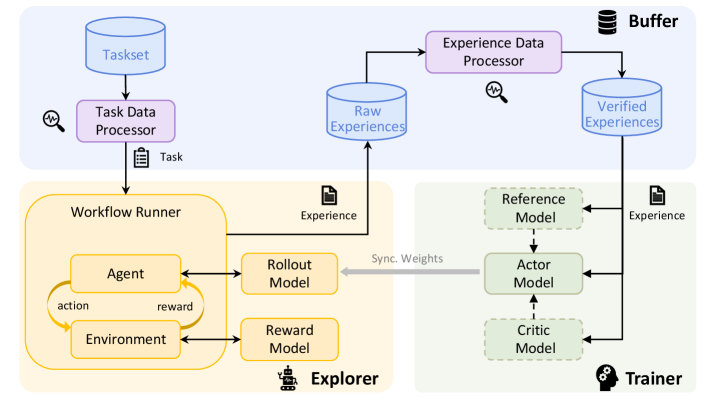
## Diagram: Reinforcement Learning System Architecture
### Overview
This diagram illustrates a reinforcement learning (RL) system architecture, depicting the flow of data and interactions between components. It includes elements for task processing, agent-environment interaction, experience management, and model training.
### Components/Axes
**Key Components**:
1. **Taskset** → **Task Data Processor** → **Workflow Runner**
2. **Workflow Runner** → **Agent**, **Environment**, **Rollout Model**, **Reward Model**
3. **Experience Data Processor** → **Raw Experiences** → **Verified Experiences** → **Buffer**
4. **Trainer** → **Reference Model**, **Actor Model**, **Critic Model**
5. **Synchronize Weights** (connects Workflow Runner and Trainer)
**Flow Direction**:
- Top-to-bottom: Taskset → Task Data Processor → Workflow Runner → Experience Data Processor → Trainer.
- Horizontal: Workflow Runner ↔ Trainer via "Synchronize Weights."
**Color Coding**:
- **Top Section (Blue)**: Taskset, Task Data Processor, Experience Data Processor.
- **Middle Section (Orange)**: Workflow Runner, Agent, Environment, Rollout Model, Reward Model.
- **Bottom Section (Green)**: Trainer, Reference Model, Actor Model, Critic Model.
- **Buffer**: Black icon with "Buffer" label.
### Detailed Analysis
1. **Taskset → Task Data Processor**:
- The Taskset (input) is processed by the Task Data Processor, which generates a "Task" output.
2. **Workflow Runner**:
- Contains an **Agent** that interacts with an **Environment** via **actions** and **rewards**.
- Uses a **Rollout Model** (predicts actions) and **Reward Model** (evaluates rewards).
- Outputs "Experience" to the Experience Data Processor.
3. **Experience Data Processor**:
- Processes **Raw Experiences** into **Verified Experiences**, which are stored in the **Buffer**.
4. **Trainer**:
- Uses **Reference Model** (baseline/expert model), **Actor Model** (policy), and **Critic Model** (value function) to train on experiences from the Buffer.
- **Synchronize Weights** ensures alignment between the Workflow Runner and Trainer models.
### Key Observations
- **Modular Design**: The system separates task processing (top), agent interaction (middle), and training (bottom).
- **Feedback Loop**: The Workflow Runner and Trainer share weights, enabling continuous improvement.
- **Experience Pipeline**: Raw experiences are filtered/verified before training, ensuring data quality.
### Interpretation
This architecture represents a closed-loop RL system:
1. **Exploration**: The Agent explores the Environment, generating experiences.
2. **Experience Refinement**: The Experience Data Processor cleans and validates data.
3. **Training**: The Trainer updates the Actor and Critic models using the Reference Model as a guide.
4. **Weight Synchronization**: Ensures the Workflow Runner’s models (e.g., Rollout, Reward) stay aligned with the Trainer’s policies.
The system emphasizes **data quality** (via verification) and **model alignment** (via weight synchronization), critical for stable RL training. The modular structure allows scalability and separation of concerns.