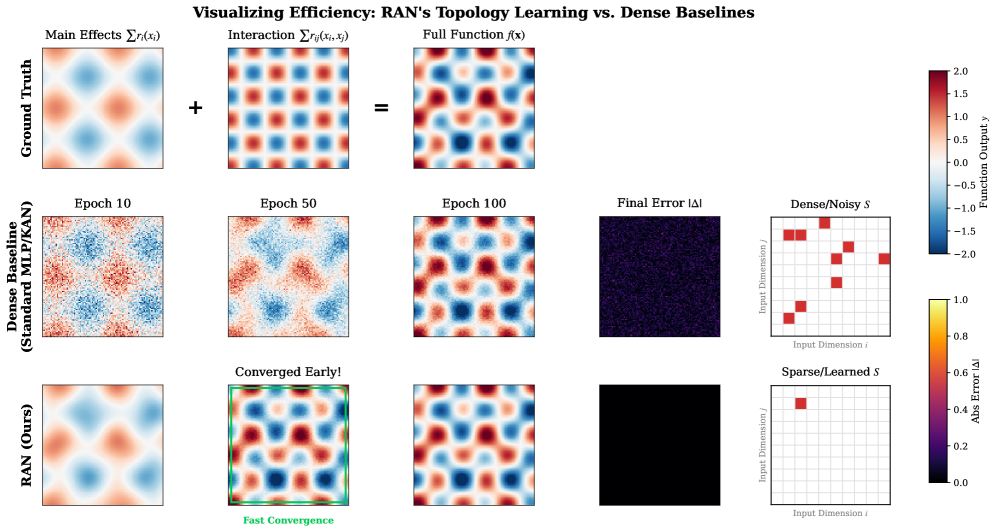
# Technical Document Extraction: RAN Topology Learning vs. Dense Baselines
## 1. Labels and Axis Titles
- **Main Title**: "Visualizing Efficiency: RAN's Topology Learning vs. Dense Baselines"
- **X-Axis Categories**:
- "Main Effects Σr(x)"
- "Interaction Σr(x,v)"
- "Full Function f(x)"
- **Y-Axis Categories**:
- "Ground Truth"
- "Dense Baseline (Standard MLP/KAN)"
- "RAN (Ours)"
- **Sub-Columns**:
- Epoch 10
- Epoch 50
- Epoch 100
- "Final Error |Δ|"
- "Dense/Noisy S"
- "Sparse/Learned S"
## 2. Legends
- **Heatmap Color Scale** (Top-Right):
- Range: -2.0 (blue) to 2.0 (red)
- Label: "Function Output y"
- **Error Metrics Legend** (Bottom-Right):
- **Dense/Noisy S**: Yellow (1.0) to Red (0.0)
- **Sparse/Learned S**: Green (1.0) to Black (0.0)
- Label: "Abs Error |Δ|"
## 3. Heatmap Categories and Sub-Categories
- **Ground Truth Row**:
- Smooth gradient across all columns.
- **Dense Baseline Row**:
- **Epoch 10**: Noisy, scattered patterns.
- **Epoch 50**: Increased structure with residual noise.
- **Epoch 100**: More defined patterns but persistent noise.
- **Final Error |Δ|**: Dark purple (high error).
- **Dense/Noisy S**: Red squares (high error).
- **Sparse/Learned S**: Single red square (high error).
- **RAN Row**:
- **Epoch 10**: Emerging structured patterns.
- **Epoch 50**: Clearer structured patterns.
- **Epoch 100**: Stable, high-contrast patterns.
- **Final Error |Δ|**: Black (low error).
- **Dense/Noisy S**: No squares (no error).
- **Sparse/Learned S**: Single green square (low error).
## 4. Error Metrics Table
| Input Dimension / | Dense/Noisy S | Sparse/Learned S |
|-------------------|---------------|------------------|
| 1 | Red | Green |
| 2 | Red | Green |
| 3 | Red | Green |
| 4 | Red | Green |
| 5 | Red | Green |
## 5. Key Trends and Observations
- **Ground Truth**: Consistent smooth gradient across all columns.
- **Dense Baseline**:
- Gradual improvement in pattern definition from Epoch 10 to 100.
- Persistent noise in later epochs.
- High final error (dark purple).
- Multiple high-error points in "Dense/Noisy S" and "Sparse/Learned S".
- **RAN**:
- Rapid convergence to structured patterns (green border at Epoch 50).
- Stable, high-contrast patterns by Epoch 100.
- Near-zero final error (black).
- No errors in "Dense/Noisy S"; single low-error point in "Sparse/Learned S".
## 6. Spatial Grounding of Legends
- **Heatmap Color Scale**: Top-right corner, aligned with heatmap gradients.
- **Error Metrics Legend**: Bottom-right corner, adjacent to error metric columns.
## 7. Trend Verification
- **Dense Baseline Heatmaps**: Noise decreases slightly over epochs but remains significant.
- **RAN Heatmaps**: Patterns stabilize and sharpen over epochs, indicating faster convergence.
- **Error Metrics**: RAN achieves near-zero error, while Dense Baseline retains high error.
## 8. Component Isolation
- **Header**: Main title and x-axis categories.
- **Main Chart**: 3x5 grid of heatmaps and error metrics.
- **Footer**: Error metric legends and convergence annotations.
## 9. Additional Notes
- **Convergence Annotation**: "Converged Early!" with green border at Epoch 50 (RAN row).
- **Language**: All text in English. No non-English content detected.